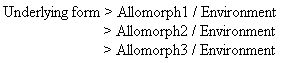| (2) |
|
Lexicography is the study of words along with the principles and procedures for describing them in a dictionary. A language contains many words, each of which must be described phonologically, grammatically, and semantically. So the task of completely describing the words of a language is huge. Dictionaries are also rather complicated things, because they attempt to describe complicated mental structures and linguistic behavior. So the task of understanding the complexity and keeping everything straight is difficult. The lexicographer must collect, record, analyze, refine, print, and otherwise manage the data. So the task requires a number of skills and tools.
FieldWorks Language Explorer has been designed to make this task as easy, straightforward, and efficient as possible. It has powerful tools for collecting words, developing entries, editing fields, and generating publishable documents. By managing the complexity and reducing much of the tedium of data processing, Language Explorer frees researchers to do what computers cannot: analyze the data and make decisions as to how lexemes should be represented in the dictionary.
The purpose of this paper is to introduce you to various issues in lexicography and how they are handled in Language Explorer. You can either read through the whole paper or use it as a resource whenever you encounter a problem in lexicography or a feature of the program that you don't understand. Section 2 "Key issues" introduces some key strategic and conceptual issues in lexicography that have influenced the design of Language Explorer or have influenced my own approach to lexicography. Section 3 "Important concepts and how to handle them" describes various linguistic units and issues in lexicography, and explains how to handle them in Language Explorer. Section 4 "Recommended step by step procedure for developing a dictionary" presents my personal view about how to produce a dictionary in an efficient and effective way, especially for languages that have been inadequately documented and described. Section 5 "A grand tour of Language Explorer" explains many of the features, areas, and fields in Language Explorer and how to use them to produce a dictionary. Section 6 "The entry" briefly describes the structure of an entry in Language Explorer and then describes each field in the Lexicon Edit-Entry pane.
The examples in this paper are often made up on the basis of my own research. Sometimes they are based on information in The American Heritage Dictionary Morris (1978), Longman Language Activator Summers (1993), Longman Dictionary of American English Summers and Gadsby (2002), The Merrian-Webster dictionary Woolf (1974), or Greek-English Lexicon of the New Testament Based on Semantic Domains Louw and Nida (1989). In each case I have shortened or adapted the entries to fit my purpose. So any inadequacies in the examples are due to my editing.
The views presented in this paper are my own. I alone am to blame for any inaccuracies or bad advice. Language Explorer has been under development for many years and is still being developed. In preparation for the most recent release of the program (November, 2014) I have revised and expanded this paper. I have attempted to accurately describe how the program currently works, but may have missed some recent changes or failed to find and correct out-of-date statements.
In order to produce a dictionary we must understand some of the issues lexicographers face and the nature of the subject we seek to describe.
The following are some crucial observations about dictionaries and the implications for what we do.
There are approximately 6,000 languages in the world. Linguists estimate that there are an average of 25,000 unique words in most languages. If we count lexical phrases and secondary senses, there are around 50,000 lexical units in most languages. Most lexemes require around 20 fields to adequately describe them. Each field contains an average of 10 characters. So to completely describe all the lexemes of every language means that we have to collect and type 60,000,000,000 characters.
With huge numbers such as these, efficiency is not an option. It must be an essential feature of our strategy. It would take an unacceptable amount of time to type all the data and edit it one piece at a time. We must find efficient ways to enter and edit data if we want to make rapid progress. In Language Explorer the Collect Words tool and the Bulk Edit Entries tools were specifically designed to meet this need.
Consider the following view of a Koine Greek dictionary database:
| (1) |
|
Consider that there are approximately 50,000 lexical units (including lexical phrases and senses) in most languages. Therefore, if this table were complete, there would be 50,000 rows. On the other hand, there are only around 50 fields needed for even the most complex and complete entry for a lexeme. So, if this table were complete, there would only be 50 columns. That means that there are 1,000 times more rows than columns.
If you filled out one entry (row) at a time, you would have 50,000 tasks. But if you filled out one field (column) at a time, then you would only have 50 tasks. I would rather do 50 tasks than 50,000. It is for this reason that Language Explorer has tools for filling in an entire column quickly, efficiently, and consistently. In fact you can fill in many fields semi-automatically using the tools in the Bulk Edit Entries pane. For the actual procedures for doing this see section 4.
Language Explorer makes it possible for you to work on one entry at a time or one field at a time. For instance you could start with the first entry in your database and fill in each field in the entry, then go on to the next entry, and so on until you reached the last entry. Alternatively you could start with the first field and fill it in for every entry in your database, then go on to the next field, and so on until you finished filling out each field. Actually it is necessary to work both ways. There will be times when you will need to add an entry and fill it in completely. There will be other times when it is better to fill in one field for each entry. For instance you could add the grammatical category (part of speech) for all the lexemes at once. Some fields, such as the Definition field, have to be filled in one at a time; and there are some tasks that require you to go through each entry in your dictionary one at a time.
You might think that it doesn't really matter whether you work one row at a time or one column at a time. But it takes a lot of time to produce a dictionary one entry at a time and there is very little we can do to help you speed up the process. However there is a great deal we can do to help you fill in a particular field in an efficient way. It is sometimes possible to work 100 or even 1,000 times faster when filling in a field for each entry. (This is no exaggeration.) So, as much as possible, you should work on one field at a time. I think you will find that it is far more efficient, and you will get far more done, if you work one field at a time, rather than working one entry at a time. Whenever you can, work the columns, not the rows.
Once you have filled in as many fields as you need, then you will go back and edit each entry. But you will be editing—correcting and polishing, rather than doing a lot of tedious typing.
It might help to understand this principle by thinking of an analogy. When someone cooks a meal of rice, vegetables, and meat, they do not cook one grain of rice, then one piece of vegetable, then one piece of meat, then another grain of rice, another piece of vegetable, another piece of meat, and so on. Instead they cook all the rice at one time, all the vegetables together, and all the meat together. No one would cook thousands of grains of rice one at a time. It is far more efficient to cook them all together. In the same way it is far more efficient to "cook" all the grammatical categories at one time, all the pronunciation fields together, and all the reversal entries together.
A computer can perform repetitious actions, but it cannot make decisions. Some of the actions involved in producing a dictionary are repetitious. For instance you need to indicate the grammatical category of each word. In a large dictionary there are thousands of nouns and verbs. So you need to decide which words are nouns and which are verbs. But once you have decided, you have to type "noun" or "verb" and you have to do this thousands of times.
One of the best uses of a computer is to do repetitious, automatic, or semiautomatic actions. Whenever I find myself doing something over and over again, I try to find a way to get the computer to do it for me, or at least help me. This is especially true of repetitious, tedious typing. The computer can often do the typing, freeing me to make the decisions that only I can make. As much as possible you should avoid spending time on repetitious tasks. For this reason, Language Explorer contains tools that “do the typing” for you. These tools can also enable you to achieve a higher level of accuracy and consistency.
For instance there are techniques for identifying the grammatical category of many words (which I describe in Section 4.2.4 "Specifying the grammatical category"). Briefly, you ask Language Explorer to filter the database for words that contain a particular affix (for instance the English derivational suffix -ment, which turns a verb into a noun). The program can do this in seconds. Then you ask it to assign the correct grammatical category to those entries. This also takes just a few seconds. Using this technique, you can sometimes assign the correct grammatical category to hundreds or thousands of words at once. This can save you days of tedious typing.
There are many kinds of languages and many kinds of dictionaries. Some languages have lots of affixation, others have little. Some dictionaries are monolingual, others are bilingual. It would seem that flexibility would be essential and standardization impossible. To a degree, that is true. A comparative dictionary of 40 related languages is very different in structure and content from a monolingual dictionary. There are programs that would enable you to do both. But such programs pay a very heavy price. They cannot constrain the data in any significant way. This permits the user to be flexible, but it also permits the user to make lots of mistakes. Such programs have limited power, because the tools cannot assume anything about the data.
On the other hand standardization opens up possibilities that flexibility rules out. For instance the structure of the data can be standardized so that the user does not have to master the structure. This reduces the level of training required of the lexicographer and enables him to concentrate on other things. Standardization eliminates many errors that occur in unconstrained databases. Standardization permits the development of tools that require the data to be in a certain form.
An analogy might help to understand this principle. Machines are often held together with bolts. Almost every bolt used today has a head with six sides. Some old bolts had heads with four sides. It would also be possible to make a five-sided head or a seven-sided head, but manufacturers have decided to standardize and use six sided heads. This makes it possible for millions of us to have a few standardized tools that work on all standardized bolts. Otherwise we would need a set of tools for four sided heads, another for five sided heads, and so on. For instance a wrench (spanner) for six sided heads would not work on a five sided head. Standardization makes life a lot simpler and more efficient for all of us.
Language Explorer has chosen to standardize some features, while permitting flexibility for others. There are pros and cons to both standardization and flexibility, but some standardization is necessary for four primary reasons.
Unfortunately there is a down side to this choice. Language Explorer cannot support every kind of dictionary imaginable. At the current state of development Language Explorer only supports the production of a dictionary that describes a single language. The description may be in the same language (i.e. a monolingual dictionary), or the description may be in a second language (i.e. a bilingual dictionary). In fact you can set up many analysis languages (languages you use to describe the words). But you currently cannot produce a truly bilingual dictionary (i.e. L1-L2 and L2-L1) in the same project.[1] To do that, you would have to set up two separate projects in Language Explorer. You also cannot produce a comparative dictionary. To do that, you would need to use an unconstrained program such as Toolbox.
One of the things Language Explorer has standardized is the fields you see in the Entry pane of Lexicon Edit. The team that designed Language Explorer included the fields they believe are most often needed and structured them in a linguistically sound way. You cannot delete any of these fields. But you can hide them if you don't want to use them. Lexicography consultants have found that every lexicographer has trouble being consistent in labeling and ordering fields. Mistakes can cause serious errors when you print your dictionary, resulting in wrongly formatted material or lost data. So Language Explorer has chosen to standardize the fields to help you avoid errors and make your job easier.
Although Language Explorer has opted for standardization, that doesn't mean that the program is entirely inflexible. You can set up custom fields for special needs. You can use multiple scripts to transcribe vernacular words. You can set up multiple analysis languages. You can determine which fields you will use and which fields you see in each display. You can specify which entries will be exported for publication. You can specify which fields will be exported and how they will be formatted. This allows you to maintain a single database, yet produce multiple publications.
The Language Explorer team has tried to strike a happy balance between standardization and flexibility. They have standardized where it seemed beneficial and allowed for flexibility where it was needed. I hope you will be happy with their choices.
Lexicography is not an easy task. The lexicographer must have a background in many fields of linguistics--phonology, grammar, semantics, sociolinguistics, historical linguistics, to name a few. To use a computer the lexicographer must have basic computer skills. He must be able to manage a large project. It would seem that the task requires a professional lexicographer. But many dictionaries have been produced by field linguists, anthropologists, language learning specialists, and others.
Sometimes the question is asked, "How can we make lexicography accessible to native speakers of a language who wish to produce a dictionary of their own language, but do not have training in linguistics or lexicography?" One of the goals of SIL is to empower local people with limited resources to develop their own language. It would be nice if there was a professional lexicographer who was available to work on each language in the world and who was also a native speaker of the language. Even if there were, there frequently isn't much money available to fund minority language dictionaries. In order to produce a dictionary for every language in the world, we must recruit more lexicographers, raise more funds, or make it possible for non-linguists to help.
There is no way to simplify language. But there are ways to simplify the process of investigating and describing it. The primary means of doing this is to divide the task into manageable steps and simplify each step. A step can be made easy by working out a method of accomplishing the step and providing everything a person needs to do that step.
For instance the first step in producing a dictionary is to collect words. But the process of collecting words has always been difficult and slow. So I developed a method of collecting words that is highly efficient and easy. The materials and tools necessary to collect words and enter them have been incorporated into Language Explorer in the Collect Words area. The method is easy to learn. Non-linguists can be taught to collect and enter words into the program in about ten minutes. For more on the word collection method see the Rapid Word Collection website (http://rapidwords.net/).
We cannot make the total process of producing a dictionary so easy that a non-linguist can do it all. Certain steps, such as determining which grammatical categories exist in the language, require input from a linguist. A computer powerful enough to run Language Explorer (or any other dictionary software) is not a simple machine. Often special fonts and keyboard managers must be installed. It is unrealistic to assume that a poorly educated person can produce a linguistically sophisticated dictionary. But an illiterate person can help to collect words. Language Explorer empowers people to participate in the process by enabling them to do specific steps. In addition there are many educated people who speak minority languages who can produce a dictionary if they have the resources and training.
It is easy for someone beginning a dictionary project to be overwhelmed by the magnitude of the task and the complexity of a program like Language Explorer. The team that developed Language Explorer tried to simplify the task and deal with the complexity. They paid attention to the methodology and mechanics of doing each step involved in producing a dictionary. They reduced the complexity in various ways. For instance some features are built into the program so the user doesn't have to deal with them. They also provided options, such as hiding fields, to limit what the user sees on the screen. They continue to develop shortcuts and eliminate clunky features such as unnecessary mouse clicks. You can help by joining the FLEx users group (http://groups.google.com/flex-list/subscribe?hl=en) where you can ask questions and make suggestions for improvement.
Having said all this, we still recognize that Language Explorer is a complicated program. So SIL has developed a companion program, WeSay, that can be used by native speakers of a language to do much of the basic data gathering. WeSay was designed to be used on portable battery-operated computing devices in remote locations. Data collected in WeSay can be read by Language Explorer. For more on WeSay see their website (http://www.wesay.org/wiki/Main_Page).
If you follow the methodology suggested in this paper, you will gradually be introduced to the features of the program that support dictionary making. There is no need for you to be overwhelmed by the power and array of features built into the program. This document, together with the demo movies and help files, will lead you step by step from setup to the completion of the project. SIL is developing resources, tools, and training materials to help you. In this way we are doing our best to empower you to easily and efficiently produce a massive, well-developed dictionary that would be the envy of previous generations of lexicographers.
The first large computerized text corpus of English was developed in the 1970s. When lexicographers started using this corpus to investigate the meaning and usage of words, they were surprised at how often the data in the text corpus was at variance with their dictionary entries—entries that had been written on the basis of native speaker intuition. They found that many words were used in ways that no dictionary described. In other cases the dictionary definitions weren't quite right or the example sentences were not typical of how the word was used.[2] It appeared that the native speaker intuition of lexicographers had sometimes failed. Why is this?
It appears that we are very much aware of some aspects of language, while other aspects are buried deep in our subconscious. We can illustrate this from phonology. Most people have no problem recognizing that the words 'divine' and 'divinity' are related both in form and meaning. These facts are ‘obvious’ to us. But most people are not aware that they change the pronunciation of 'divine' when the suffix '-ity' is added to it. 'Divine' [dɪvajn] becomes 'divin' [dɪvɪn] because of a phonological rule. People make the change entirely subconsciously and are only aware of it when it is pointed out to them.
Similarly many aspects of the way we use words are buried in our subconscious. We only become aware of them when they are brought to our attention. This is the great benefit of the text corpus method. Studying actual examples of usage brings to our attention those rules of usage that are buried in our subconscious. Because of this lexicographers concluded that dictionaries ought to be based on text corpus evidence and that intuition alone is unreliable. They still needed their native speaker intuition to make sense of the text corpus data and to supply information that cannot be gleaned from texts. But the text corpus method revolutionized lexicography for major languages.
Corpus linguistics has developed into a significant branch of linguistics, with its own methods, software, theories, and insights. There is certainly more to linguistics and lexicography than just corpus studies. In fact I would say that it is just one tool available to us. But we would be very foolish indeed to neglect this growing field.
Unfortunately lexicography for minority languages has lagged behind this trend because lexicographers working on minority languages face several unique problems. In some languages there are no written texts of any kind. You can hardly employ the corpus method with no texts. In some cases the creation of a text corpus may first require the development of an orthography, the development of a literacy program, and the development of a literature by encouraging people to start writing. An alternative is to record (or video) oral literature, speeches, and conversations and then employ someone to transcribe the recordings.
Some languages are highly inflecting. These languages require a linguist to develop a parser that can annotate the texts and indicate the lexeme form (or citation form) of each inflected word. The reason is that a concordance program cannot work adequately when there are scores, hundreds, or even thousands of possible inflected forms of each stem. A concordance program must be able to pull together all the inflected forms of a stem and display them together.
Minority languages often lack sufficient resources to develop a large corpus. It takes time and money to collect texts, transcribe oral texts, and enter the data into the program. It takes a linguist with good computer and analytical skills to develop a parser.
Even if your resources are seriously limited, you should collect as many texts as you can and add them to the text corpus in Language Explorer. If you have a text that has been typed, you can cut and paste it into Language Explorer without having to go through a complicated import procedure. So you can build a text corpus as fast as you can collect texts.
Language Explorer also has an interlinearizer and a built in parser that enable you to analyze inflected languages. Part of the process of interlinearizing a text is to identify the lexeme form (or citation form) of each word in the text and link each inflected form to the correct dictionary entry. This in turn enables you to generate a concordance of either a particular wordform or a lexeme. So Language Explorer is designed to enable you to use the corpus method even if your language is highly inflecting.
Many of the tasks involved in producing a dictionary can be accomplished without a text corpus. But there are two steps that benefit from the corpus method. The first is collecting words. I believe that using semantic domains to collect words is by far the most efficient and effective method. But generating a list of the words that occur in your text corpus will ensure that you have all the common words in your dictionary. It will also turn up many words that the semantic domain method will miss. So I recommend that you use both methods.
The second step that benefits from the corpus method is semantic research. Although there are a number of tools for doing corpus research, the two primary ones are a tool that generates a concordance of a word and a tool that lists the collocates of a word. Language Explorer can generate a concordance, but unfortunately it does not yet have a collocate tool.
Some lexicographers have labored their entire life to produce one incomplete dictionary of a language. The job is really too big for one person. Major publishers employ large teams to work on a new edition of a dictionary. How can we work together on a single dictionary when we are scattered all over the geographical area where a language is spoken or when we want help from a consultant on another continent?
Language Explorer was designed with this need in mind. It is now possible for a team to work remotely on a single project.
The primary task of a lexicographer is to figure out what is in the mental lexicon and describe it in a published dictionary. There are major differences between the lexicon in a person's mind, a lexical database in a computer, and a published dictionary. We will discuss three major issues--the nature of the information, the organization of the information, and the presentation of the information. One reason why this is important is that we must clearly understand the difference between how information is stored by Language Explorer and how it is presented on screen and in print. It is stored in one form, but we can view it and publish it in a variety of forms.
Physicists claim they are close to describing all the laws that govern the physical universe. By way of contrast, we have barely scratched the surface of lexicography. We have no idea how the mind stores words (or even if it stores words). We have no idea how the mind accesses lexical information when we speak or listen. We have no idea if there are such things as "definitions" in the mind. We don't even know if there is anything in the mind that corresponds to a dictionary. All we can do is observe how people use language and try to describe what they do.
Think for a moment about how your brain might store the word ‘house’. We have no way of finding the place in your brain where ‘house’ is stored or knowing exactly how it stores it, but we can at least make some observations. You can pronounce the word, understand it when it is spoken, and use it in a sentence with correct grammar. You can picture a house in your mind, describe it by listing the features of a house (e.g. people live in it), tell what kind of a thing it is (a building), tell how it differs from other kinds of buildings, describe a typical house, and tell if a building should be called a house or not. But we have almost no idea how the mind stores this information, or in what form it stores it. We know what people can do with words, but we cannot observe the mind directly. So a dictionary is really a representation of information that linguists can glean from observing how people use words.
A computer programmer could tell you how a program such as Language Explorer actually stores information. For our purpose it is enough to note that we can store pieces of written material (like a definition), a picture, or a sound file. Obviously computer files are quite different from what is in your brain. The challenge is to capture the information in our brains in a form that we can put into a computer. But we are severely limited by two things--our lack of understanding of the mental lexicon, and the comparatively simple nature of computer files.
Up until recently, all dictionaries were printed on paper, and many still are. A language has a lot of words, so dictionaries tend to be big and expensive. To make them affordable, publishers want to keep them as short as possible. So they use abbreviations and short definitions to keep each entry as short as possible. But this means that printed dictionaries are only poor representations of the mental dictionary.
To illustrate this problem, consider the following dictionary entry:
| (3) |
|
The first part of the entry gives the spelling of the word. But we had to go to school to learn how to spell. We store the spelling of a word in our minds, but people who don’t know how to read and write don’t have this information.
The second part indicates how the word is pronounced, but it is in writing, too. So it is only a poor indication of the knowledge we have in our minds about how to produce the word with our mouth or how we recognize the word when we hear it.
The third part indicates the word is a noun, but we had to go to school to learn what a noun is. Somehow the word ‘noun’ is supposed to indicate how the word functions in the grammar. We know in our heads how to use nouns, but putting “n.” in a dictionary doesn’t capture what this information really is. So this is also a poor indication of what is in our heads.
The fourth part of the entry is called a definition. But we don’t really know if the brain stores definitions or some other kind of representation of a word’s "meaning."
The fifth part of the entry is an example sentence. A speaker could say this sentence, but it isn’t stored permanently in his mind.
The last part of the entry is called the etymology (the history of the word). Nobody knows this information unless they have studied the history of words. So this part of the entry doesn’t even represent what is in people’s minds. It is historical information about the word, but isn’t information that the average person stores in his head.
Today many dictionaries are published electronically. This enables us to include more information because the size of the dictionary doesn't appreciably increase the cost of publication (although it stills costs more to collect the information). The main difference between an electronic dictionary and a printed dictionary is that an electronic dictionary is much more like a dictionary database. You can attach sound files to each entry in an electronic dictionary, something that you can't do in print. The usefulness of an electronic dictionary is determined by the user interface. A good interface will allow the user to search for an entry, jump from one entry to another, listen to sound files, and even use links to access information outside the dictionary, for instance by jumping to an Internet site. So an electronic dictionary is slightly better than a printed dictionary in representing the mental lexicon, but not much. For some languages an electronic dictionary is far superior to a printed dictionary because of the difficulty of finding words. An electronic dictionary can contain many more minor entries and cross-references. Language Explorer enables you to produce an electronic dictionary that does all these things (currently via programs like Lexique Pro), but an electronic dictionary is still like a printed dictionary in that it is a poor representation of the mental lexicon.
In linguistics we sometimes use the term ‘lexicon’ to refer to all the words in a language, or to refer to all the words that exist in a single person’s mind. In this document I use the term 'mental lexicon' to refer to what is in a person's head. In contrast the term ‘dictionary’ usually refers to a published document which (we hope) is a good representation of the mental lexicon. A computer representation of the lexicon is sometimes called a ‘dictionary database’ or a ‘machine readable dictionary’. In Language Explorer the database is called the 'lexicon' and a publication (print or electronic) is called the 'dictionary'. The best way to get from the mental lexicon to a published document is to develop a computer database where we can collect, store, and develop the information. So a computer database is something in between the mental lexicon and the published document.
From this discussion it should be obvious that a published dictionary is a very abbreviated and abstract representation of the mental lexicon. We might want the two to be more similar. But a lexicographer must produce a document that people can use. So the usability of a published dictionary becomes one of the most important factors in what information we include in the dictionary and how it is presented.
Most dictionaries are organized by alphabetizing the headwords. However words are not stored in the mind in an alphabetized list. Very few people could tell you what word comes after next in the dictionary. (In my Webster’s Unabridged Dictionary McKechnie (1976) it is next-door.) Instead words are organized in groups of semantically related words. The primary evidence for this is the ease with which people can call to mind words that are related in meaning.
When we speak, we can call up words almost instantly. When we have a topic in our minds, we can call up any word we want to express some idea related to that topic. When we write, we may pause and search our minds for the best word to use in the context. So we are working from meaning to form. Therefore we conclude that words are stored in the mind on the basis of meaning.
Of course when we are listening, our minds have to work in the opposite direction. So we also store a representation of the sound pattern of words, which we access when we hear a word. But these patterns are not stored alphabetically.
The point is that the mental lexicon is organized both by meaning and by form. Therefore a published dictionary could also be organized either by meaning or by form.
So why do we alphabetize dictionaries? We do so because the form of words is easily accessible to our conscious minds. We have learned our ABC's. We have learned to read. We have learned how words are spelled. So we can find words that are listed alphabetically. When we alphabetize a dictionary, our primary concern is to make it easy for the user to find the word he is looking for.
Unfortunately the meaning of words has not been codified in a rigorous system like the form of words has been through writing. Consequently it is more difficult to find words in a meaning-based dictionary. Even so, a meaning-based dictionary is extremely useful. A writer or translator may be searching for alternate ways to express a particular meaning. He is working from meaning to form. For him an alphabetized dictionary is almost useless because it works from form to meaning. He needs something like a thesaurus that is organized by meaning. So there is a value to both form-based (alphabetized) and meaning-based dictionaries. Language Explorer enables you to produce both.
Form and meaning are just two pieces of information in each entry. Language Explorer enables you to sort the dictionary on any field in browse view. It also enables you to filter the dictionary in powerful ways to find the information you want to work on. The combination of the various views, the sort function, and the filter function enables you to organize your data in many creative ways to make it easy to enter, view, analyze, and edit the data.
One of the most significant ways in which the mind organizes the mental lexicon is by forming links between pieces of data. A particular form is linked to a particular meaning, or to several meanings. A particular meaning is associated with a particular grammatical pattern of use. A form may be linked to another form, for instance a derivative. The meaning of one word may be linked to the meaning of another, for instance as synonyms or antonyms. Some of these links are captured in Language Explorer simply through the structure of an entry. Other links, for instance those between forms, must be created by you. Because there are a variety of kinds of relationships, there are several systems used by Language Explorer to link different kinds of data. One system enables you to link forms that are morphologically related to each other. Another system enables you to link a sense of one entry with a sense of another entry using what are called lexical relations. These links enable you to do two basic things, (1) link the two pieces of data, and (2) specify the kind of relationship between them.
Language Explorer uses what is called a "relational database." This makes is a very powerful tool for linking various pieces of information together. It also makes it a powerful tool for organizing and displaying the information in creative and powerful ways.
It is important to recognize the difference between data itself and the presentation of that data. Language Explorer takes care of storing the information you collect on your computer. Unlike some dictionary software, it stores your data in a series of database tables. It is very difficult to read the information directly from the tables. So Language Explorer displays the information on screen in a form that we can read and interact with. All computer programs store information in one form (ultimately in binary code), but display it on screen in a form we can understand. A simple program will display a simple file, such as a straight text file, in only one way. But a sophisticated program like Language Explorer can present your data on screen in many different ways. We call these 'views' of the data. The data is the same in all the views, but we can select what we see and how it is arranged on the screen. We can also decide how it will be presented for publication.
There are three basic types of views in Language Explorer--edit view, browse view, and publication view. An edit view separates each field in a record and places each field on a separate line. This makes it easy to see and edit each field in a record. A browse view places each record on a separate line and puts each field in a separate column. This makes it easy to compare the data in several records at once. A publication view shows how the data will look (or could look) when it is published.
The program has several edit and browse views to enable you to enter and edit your data in powerful ways. You can edit the data in the browse views as well as the edit views, although there are limitations on what fields you can edit in the browse views. You can change these views in a number of ways to make it easier to accomplish different tasks.
The program also has several publication views in the Lexicon pane--Dictionary, Classified Dictionary, and Reversal Indexes. You cannot edit the data in any of these views. They are included merely to show you how your data could look in print. However you can change various settings in the program that change how the data is presented. You can also export the data in various formats, such as XML, SFM, or LIFT. The exported file can then be processed by other software, such as Lexique Pro, in order to format it for printing or for publication on the Internet. In this way Language Explorer makes it possible to maintain a single database, but export the data in multiple formats for various kinds of dictionaries.
The primary view of the data is called the Lexicon Edit view. It is a combination of each of the three basic types of views. The left pane is the Entries pane which consists of a browse view. The right pane is the Entry pane which displays a single entry at a time. When you select an entry in the Entries pane, it will be displayed in the Entry pane. The Entry pane consists of a dictionary view at the top and an edit view at the bottom. The dictionary view enables you to see how the entry will appear in print with the settings you have currently chosen. The edit view enables you to edit each field of the entry.
There are also three other browse views. The Browse pane is simply a browse view that fills the screen. The Bulk Edit Entries pane enables you to edit a single field and has tools that enable you to edit that field in many entries at once. It enables you to edit the columns, rather than the rows, as discussed in section 2.1.2. It automatically places each instance of the field that you want to edit on a separate line. Since an entry may have more than instance of a field, such as the Definition field or the Example Sentences field, this enables you to see all the instances of the field so that you can sort and filter them. The Bulk Edit Reversal Entries pane makes the same tools available to work on reversal entries.
There is also a very specialized view, Collect Words, that was designed to enable you to enter lots of new words efficiently using the Dictionary Development Process list of semantic domains. All of these views are views of a single database. The data is the same in each view. Language Explorer merely presents it differently in order to facilitate a variety of tasks. The rest of this paper describes how to use the tools and views in Language Explorer to get the job done.
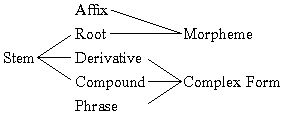
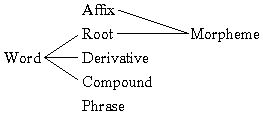
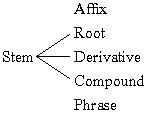
In order to produce a dictionary we must understand the various types of lexical units and how to handle them in Language Explorer. Linguists use the terms 'word', 'morpheme', 'allomorph', 'affix', 'root', 'stem', 'derivative', 'compound', and 'phrase' to refer to various kinds of linguistic units. Lexicographers use the terms 'lexeme', 'headword', 'citation form', 'complex form', and 'variant' to refer to linguistic units that are important for lexicography. They also use the terms 'main entry', 'subentry', and 'minor entry' to refer to various kinds of dictionary entries. Some of these terms are frequently confused.
It is vitally important that you understand these terms so that you put the correct information in the right field and label the information correctly. Many of the features of Language Explorer depend on fields containing the type of information they were designed for. For instance Language Explorer has special tools and features for handling variants and allomorphs. There is also a procedure for linking complex forms, such as compounds, to their roots. The program can automatically do a lot of work for you. It can cross-reference entries, create subentries in a root dictionary, create minor subentries in a stem (or lexeme) dictionary, and much else. But it can only do these things if you understand the various kinds of units and what to do with them.
The following are some basic terms and how they are used in Language Explorer.
In lexicography we use the term lexeme to refer to a unit in the mental lexicon. Sometimes the term is defined as the minimal unit of the semantic system[3] and sometimes it is used to refer to a combination of a form and a single sense. But in Language Explorer it is used to refer to the mental equivalent of a dictionary entry. So a lexeme can have more than one sense. A lexeme can be a morpheme, word, or lexical phrase, because each is a form with an associated meaning. If a lexeme is a stem, all the inflected forms of the stem are included. So a lexeme is a stem and all its inflected forms. If the lexeme has allomorphs or variants, they too are included. So a lexeme is an abstract unit. A lexeme can have more than one pronunciation and more than one meaning. It can be inflected in different ways and even belong to more than one grammatical category.
In order to be able to talk about a lexeme, we usually refer to it using its basic pronunciation. So we speak of the lexeme 'house' or the lexeme 'love'. We say that 'house' and 'houses' are forms of the lexeme 'house'; we say that 'love' (noun) and 'love' (verb) both belong to the lexeme 'love'; and we say that 'love' 'to really like something' and 'love' 'to care for someone' are two senses of the lexeme 'love'.
In Language Explorer we create an entry for each lexeme. The basic form of the lexeme is put in the Lexeme Form field. We record the allomorphs and variants of the lexeme, create a sense for each meaning, and describe all aspects of its form, meaning, and usage.
The term 'word' is something that we all understand, but is a little hard to define accurately. One problem is that people, including linguists, use the term 'word' in many ways. Linguists define a grammatical word in various ways depending on their theoretical perspective. A phonological word is the smallest thing that we can say in normal speech. An orthographic word is something written with a space (or punctuation) on either side. Unfortunately grammatical words, phonological words, and orthographic words are not always the same thing. For instance the English word 'a' is written as a separate word, but is actually a clitic.[4]
When we talk about the words in a dictionary, we sometimes use the term 'word' rather loosely. The entries in a dictionary are not all words. Some of them are affixes and some are phrases. To be more precise we could use the term 'lexeme' for a unit in the mental lexicon, 'entry' for a unit in the database, and 'article' for a unit in the published dictionary. But in order to communicate more easily and naturally, most lexicographers (including me) sometimes use the term 'word' to mean 'lexeme in the lexicon', 'entry in the database' or 'article in the dictionary'. However Language Explorer uses 'word' as a technical term to refer to an orthographic word in a text. In Language Explorer the Word Analyses area contains a list of words that occur in your text corpus. In the interlinear display the first line is called the Word line.
In Language Explorer the term 'wordform' means the same thing as 'word'. Both refer to orthographic words. The term 'wordform' refers just to the written form, irrespective of whether it has variant pronunciations or multiple meanings. The English words 'color' and 'colour' are two different wordforms. Homographs share the same wordform, even though we would say they are different lexemes. In the Texts & Words-Word List Concordance, Word Analyses, and the Bulk Edit Wordforms areas the center pane is called the Wordforms pane and contains a list of all the words in your texts. The Help files will sometimes refer to this list as the "wordform inventory." The words in the list might be inflected or uninflected. So the list of wordforms is not the same as the list of lexemes in the lexicon.
Consider the word colts. It is composed of two parts: colt and -s. Each part has a meaning. The root colt means 'a baby horse' and the suffix '-s' means 'Plural'. We use the term 'morpheme' to refer to the smallest part of a word that has a meaning. So 'colt' and '-s' are both morphemes. Morphemes can be roots or affixes.
A morpheme is not the same thing as a letter. The word 'colts' is composed of the letters c, o, l, t, and s. But as letters they have no meaning and therefore are not morphemes. Although the letter 'c' is part of the word 'colts', in the context of 'colts' it has no meaning. The letter 's' in the word 'desk' is not a morpheme, because it has no meaning in the context of 'desk'. But the 's' in 'colts' is a morpheme because it means 'Plural' in the context in 'colts'. Morphemes can consist of a single letter or a string of letters. The word 'unrealistic' is composed of a root 'real' and three derivational affixes 'un-', '-ist', and '-ic'. Each of the four parts has a meaning and therefore is a morpheme.
Some lexicographers include all morphemes in their dictionaries. Other lexicographers only include those morphemes that can occur as a full word by themselves. However in order to parse words and interlinearize texts you need to include all morphemes in the lexicon. (If you only want to parse down to the stem level, you can ignore derivational affixes.) You can include a morpheme in the lexicon but exclude it from the dictionary by putting a check in the box in the Exclude As Headword field. I would recommend that you include all morphemes in your dictionary. One purpose of a dictionary is to document and describe a language for all those who wish to know more about it. Scholars and future generations will appreciate a description of roots and affixes as well as full words and lexical phrases.
A root is a morpheme (a part of a word) that is the primary or basic part of the word. In the example 'colts' (above), 'colt' is the root. Roots like 'colt' can usually occur by themselves as full words.
If a root cannot occur by itself, it is called a "bound root." An example of a bound root is the Greek word ikhthus (written ἰχθύς in the Greek orthography), meaning 'fish'. The root is ikhthu (ἰχθύ), but it must have a suffix. The root occurs in the affixed forms ikhthus, ikhthuos, ikhthun, ikhthues, ikhthuōn, ikhthuas (ἰχθύς, ἰχθύος, ἰχθύν, ἰχθύες, ἰχθύων, ἰχθύας), but never by itself as a word. So it is a bound root, meaning that it must be bound to an affix. If a root can occur by itself without any affixes, it is called an "unbound root" or simply a "root." In order for Language Explorer to correctly parse words, it needs to know which entries are roots and which are bound roots. You specify this information in the Morph Type field.
You should create an entry for each root in your language. This enables the parser to analyze your derivational morphology. See section 3.1.4.1 for special considerations for bound roots. Language Explorer presents each root as a main entry in the published dictionary. If you don't want a root to appear in your dictionary, you can exclude it using the Exclude As Headword field.
A bound root is a root that cannot occur by itself in normal speech. It always occurs bound together with an affix or another root. You should create an entry for each bound root. When you create an entry for a bound root, you should type an asterisk (*) at the beginning of the form. Language Explorer will treat any form that begins with an asterisk as either a bound root or a bound stem.
If you want the entry to be included in your published dictionary, you should decide what form of the word to use as the headword in the dictionary article. You should put this form in the Citation Form field. If you do not want the entry to be included in your published dictionary, you should put a check in the box in the Exclude As Headword field. In the following example the asterisk indicates that the headword is a bound root and does not occur naturally in the language.
| (4) |
|
Most English dictionaries would not include an entry for a bound root such as this, because it never occurs by itself as a word. Users would generally not be interested in such entries and would very likely be confused by them. For this reason most dictionaries only use naturally occuring words as headwords.
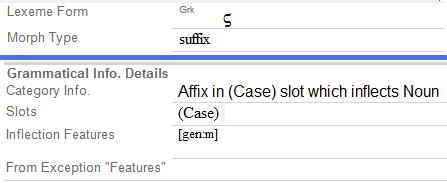
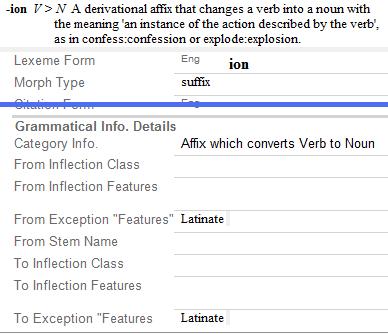
An affix is a morpheme (a part of a word) that cannot stand alone and must be attached to a root. Affixes are distinguished by two primary features--where they occur in the word, and what kind of meaning they have. Prefixes occur before the root, suffixes after the root, infixes in the middle of the root (sometimes in the middle of another affix), and circumfixes on both ends of the root. Inflectional affixes often indicate how the word functions in the grammar, or adds a meaning such as 'Plural' (for nouns) or 'Past tense' (for verbs). Derivational affixes usually change the grammatical category (part of speech) of the root or change the meaning in some important way. For instance the derivational affix '-er' changes a verb into a noun, as in 'speak/speaker', and also changes the meaning from an action to a person who does the action.
In order for Language Explorer to correctly parse words, it needs to know which entries are affixes and what kind of affixes they are. You specify this information in the Morph Type field. When you create an entry for a prefix, you should type a hyphen after it (e.g. un-). Similarly when you create an entry for a suffix, you should type a hyphen before it (e.g. -ed). Infixes are entered with a hyphen on either side (e.g. -em-). Circumfixes are entered with two hyphens with a space in between (e.g. ka- -an). This tells the program that it is an affix and what kind of affix.[5] Language Explorer will treat any form that begins or ends with a hyphen as an affix.
You should create an entry for each affix in your language. The primary reason is so that you can interlinearize texts. But it is also important to document all the morphemes in your language. Even if you don't want entries for affixes in your published dictionary, it is good to include them in the database. Future generations of scholars will look at your dictionary for information on how the language was spoken today.
If you want the entry to be included in your published dictionary, you should decide what form of the affix to use as the headword in the dictionary article. You should put this form in the Citation Form field. If you do not want the entry to be included in your published dictionary, you should put a check in the box in the Exclude As Headword field. For more on affixes and how to handle them see Andy Black's 'Introduction to Parsing' under in the Help-Resources menu.
You should create an entry for each inflectional affix in your language. See section 3.1.5 for the reasons for doing this and for the procedure. Some lexicographers prefer to deal with inflectional affixes in the Grammar Sketch, a table, or an appendix. However many users, especially language learners will look up an affix to find out what it means. In the following three entries, the first two are inflectional affixes and the third is a derivational affix.
| (5) |
|
| (6) |
|
| (7) |
|
You should create an entry for each derivational affix in your language. You should do this so that you can use the parser to analyze derivational morphology. You should also do this in order to document all aspects of your language. However most published dictionaries do not include derivational affixes. The reason is that most users are not linguists, do not understand derivational morphology, and would very likely be confused by an entry for a derivational affix. However there may be some productive derivational affixes that users would be interested in, such as the following:
| (8) |
|
Language Explorer enables you to parse on a root or stem level. Parsing on the stem level means that the parser will identify inflectional affixes but ignore derivational affixes (and compounding). Parsing on the root level means that the parser will also identify derivational affixes and multiple roots in compounds. To parse on the stem level you should only enter inflectional affixes into the database. To parse on the root level you should also enter derivational affixes. If you enter both, the parser will propose multiple analyses. To prevent this complication you must somehow eliminate the derivational affixes.[6] One requirement for parsing on the stem level is that you must enter stem "allomorphs" into the database. Technically stems don't have allomorphs, only morphemes do. But in order to parse on the stem level we have to treat stems as if they were morphemes in this respect. You should enter alternate forms of a stem in the Allomorph section of Lexicon Edit-Entry. The Allomorphs section is used to record alternate forms of stems as well as true allomorphs (alternate forms of morphemes).
A stem is a word or part of a word that doesn't have any inflectional affixes added to it.
There are six basic kinds of relations between lexical forms: (1) morphemes and allomorphs, (2) basic forms of lexemes and variants, (3) stems and inflected forms, (4) roots and complex forms, (5) homonyms, and (6) lexical relations. The first four involve a relation between a basic form and another form based on it. The fifth kind, homonyms, is when two words are the same in form, but unrelated in meaning. The sixth kind, lexical relations, involves a semantic relationship between lexemes. Allomorphs and variants are similar in that they are alternate forms of a lexeme that are used in different environments. Inflected forms and complex forms are similar in that they are composed of more than one morpheme. Once we understand these six kinds of relations, we can understand many of the issues involved in structuring our data.
An allomorph is an alternate form of a morpheme. For instance the root stop has the form stop in the word stops, and the form stopp in the word stopped. A morpheme sometimes only has a single form. In this case you would enter the form in the Lexeme Form field. If a morpheme has more than one form, each form is called an allomorph. If one allomorph is more basic than the others, you would put the basic form in the Lexeme Form field. The other allomorphs should be entered in the Allomorphs section of the Entry pane. Click anywhere in the Allomorphs line. Then click the Insert Allomorph link. Type the form of the allomorph in the Stem Allomorph field. (If the lexeme is an affix, this field will be called the Affix Allomorph field.) Use the other fields as needed. If you need to enter another allomorph, click the Insert Allomorph link again. Another bundle of allomorph fields will appear.
Not all morphemes have allomorphs. But some do when something in the context causes the morpheme to change in form. Usually the contextual factor is phonological, but sometimes it is due to the inflection class of a neighboring morpheme. The plural suffix in English is an example of a morpheme with allomorphs. It has the form -s following a voiceless consonant as in cats [kæts], -z following a vowel or voiced consonant as in dogs [dagz], or -ɨz following a sibilant [s, z, ʃ, ʒ, ʧ, ʤ] as in foxes [faksɨz]. Some linguists would say that -z is the underlying form (even though we normally write it with an s), since the other two allomorphs can be derived from it by simple rules. The relationship between an underlying form and its allomorphs is often expressed by a rule in the form:
Different theories express the rules using features, natural classes, or other theoretical devices. Currently Language Explorer only supports natural classes. You define the classes in the Grammar-Natural Classes area. You define the environments in the Grammar-Environments area. Then for each allomorph you select the appropriate environment from the list of environments in the Environment field in the Entry pane in Lexicon Edit. An environment can make use of a natural class, such as /_[V] (before vowels), or simply use a string of characters, such as /_tion.
Roots can also have allomorphs, as in divine [dɪvaʲn] and divinity (divine + -ity) [dɪvɪnɪti]. We can say that the allomorph [dɪvaʲn] is the underlying form, since the allomorph [dɪvɪn] is derived by a rule that shortens a vowel when it is followed by a two syllable suffix such as -ity [-ɪti].
Sometimes it is difficult to pick one of the allomorphs as the underlying form. For instance all four allomorphs of the im-/in-/ir-/il- prefix in the words impossible [ɪmpasɪbļ], intangible [ɪntænʤɪbļ], incomplete [ɪŋkǝmplit], irreplaceable [ɪrʌplesɪbļ], and illicit [ɪlɪsɪt] are formed by rules from an abstract form that we can symbolize as iN-. We would say that iN- is the underlying form. We would not normally put abstract forms in a published dictionary, since most people wouldn't understand the symbols we use (such as using a capital letter to indicate a archiphoneme). Instead we would give the abstract form in the Lexeme Form field, but put one of the allomorphs in the Citation Form field so that it will be used as the headword in the published dictionary. We also have to indicate that iN- is an abstract form so that the parser doesn't try to use it. We do this by putting a check in the box in the Is Abstract Form field.
Allomorphs are treated together in a single entry because they are merely alternate forms of the same lexeme. It is important to record information about allomorphs if you want to use the parser to interlinearize texts. But most published dictionaries ignore allomorphs, since the average user is not even aware of them. You can configure the Dictionary view to include them if you want. Some lexicographers may want to explain when allomorphs are used. There is currently no field specifically devoted to a prose discussion of allomorphs, but you can set up a custom field for it and configure it to be displayed in Dictionary view. Do not create a separate entry for an allomorph unless for some reason you want to create a minor entry for it in your published dictionary. For instance if you created an entry for the prefix 'in-', you might possibly also want to create a minor entry for its allomorph 'im-'. If you want an allomorph to appear in your dictionary as a minor entry, you must create a separate entry for it in the database and treat it in the same way as a variant.
Allomorphs are handled differently than variants. The reason for this is because allomorphs are conditioned by phonological and grammatical features in the linguistic environment. The parser needs to know what these features are in order to correctly parse words. In contrast variants are conditioned by pragmatic or sociolinguistic factors in the extra-linguistic environment. The parser cannot access these factors. So as far as the parser is concerned variants are essentially unconditioned. Traditionally variants are listed in a published dictionary, but allomorphs are not. For more on handling allomorphs see Andy Black's 'Introduction to Parsing' in the Help-Resources menu.
In some languages there is a difference between phonological allomorphs and orthographic allomorphs. For instance 'divine' has two phonological allomorphs [dɪvaʲn] and [dɪvɪn] (dɪvɪn-ɪti) as well as two orthographic allomorphs 'divine' and 'divin' (divin-ity). But note that the orthography does not exactly represent the phonological difference. Next compare 'wage' and 'wag-ing' with 'wag' and 'wagg-ing'. 'Wage' only has one phonological allomorph [weʲʤ], but has two orthographic allomorphs 'wage' and 'wag'. Likewise 'wag' has one phonological allomorph [wæg] and two orthographic allomorphs 'wag' and 'wagg'.
Next consider the allomorphs of 'iN-' 'NEG' in 'impossible' [ɪmpasɪbļ], 'intangible' [ɪntænʤɪbļ], 'incomplete' [ɪŋkǝmplit], irreplaceable [ɪrʌplesɪbļ], and illicit [ɪlɪsɪt]. Note that there are four phonological allomorphs [ɪm], [ɪn], [ɪŋ], and [ɪ], and four orthographic allomorphs 'im', 'in', 'ir', and 'il'. This mismatch of phonological and orthographic allomorphs will be common in languages with "morphophonemic" orthographies.
How do we handle this sort of complexity? For the English prefix 'iN-' we could do it this way:
It is sometimes necessary to enter an alternate form of a stem. In linguistics an allomorph is an alternate form of a morpheme, not a stem. So technically stems do not have allomorphs. But when we interlinearize a text, we often do not want to parse a word all the way down to its roots. Instead we ignore derivational affixes and only analyze inflectional affixes. When we do this, we often find that a stem has more than one form. For instance the word 'popularize' is composed of the root 'popul' (cf. populace, population, populous), the suffix '-ar' and the suffix '-ize'. But when we interlinearize an inflected form such as 'popularizing', we just want to indicate that it is composed of the stem 'popularize' and the suffix '-ing'. But the form of the stem in 'popularizing' is actually 'populariz', not 'popularize'. The silent 'e' is dropped when the suffix is added.
Language Explorer handles alternate forms of a stem in the same way as allomorphs. You would not create a separate entry for an alternate form. Instead you enter the alternate form in the Allomorphs section of the Entry pane. See section 3.2.1 for instructions on how to do this.
A variant is an alternate form of a lexeme. A variant is like an allomorph in that both are alternate forms. But an allomorph is an alternate form of a morpheme and a variant can be an alternate form of any kind of lexeme. Allomorphs are conditioned by phonological or morphological factors, while variants are conditioned by a wide range of socioloinguistic factors. Consider the following pairs of words:
| (11) |
|
| (12) |
|
| (13) |
|
| (14) |
|
| (15) |
|
| (16) |
|
These are all examples of various kinds of variants. Example (11) is a spelling variant between American and British English. Although the word is pronounced differently in the two dialects, the difference is regular. So this would not be considered an example of a pronunciation variant. To be a pronunciation variant the difference would have to be irregular.
Example (12) is a dialect variant, which in this case is also both a pronunciation variant and a spelling variant between standard English and Southern American English.
Example (13) is a social variant, which means that it is a pronunciation variant determined by social class.
Example (14) is a register variant. The word 'interesting' can be pronounced 'intresting' in informal speech and pronounced 'ineresting' in fast speech. We call variants like these 'register variants' because they are used in different registers such as formal speech versus informal speech, slow speech versus fast speech, and oral versus written expression.
Example (15) is a free variant, which means it is a pronunciation variant that is unconditioned. Most “free” variants are actually conditioned, but the factors may be difficult to determine. So they appear to be unconditioned.
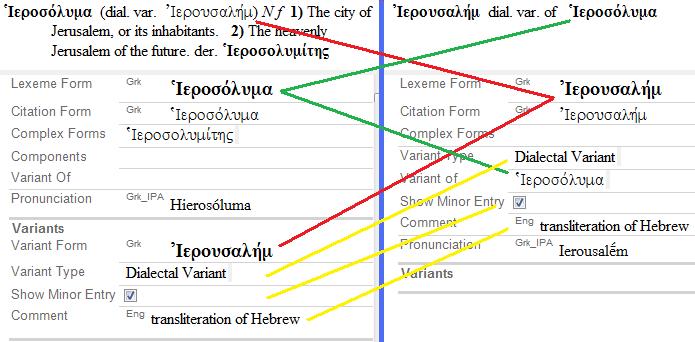
Example (16) is a dialect variant between British and American English in which a different lexeme is used. (See below for how to handle this situation.)
Variants are irregular forms of a lexeme that are conditioned by pragmatic or sociological factors. The first thing you must do is determine which form of the lexeme is the normal or basic form. The headword of a dictionary article stands for all the variants.
You handle variants by first creating an entry for the primary form. Then you enter the variant in the Variants section toward the bottom of the Entry view. You specify the type of variant in the Variant Type field. The variant type is chosen from a list. Since there are many types of variants, Language Explorer allows you to add your own variant types to the Variant Types list in the Lists area. For instance you can set up a variant type for a specific dialect.
When you add a variant, Language Explorer automatically creates a separate entry for it. There are several reasons for this. One reason is that the parser needs to know how to handle the form. If the variant has allomorphs or belongs to a different inflection class, you would indicate this in the entry for the variant. You may also want to display the variant as a minor entry in the published dictionary. If you choose to display a variant as a minor entry, you may want to include information of various kinds, such as how the variant is pronounced, or give an example sentence to indicate how the variant is used. In order for the program to be able to do these things, it is necessary for variants to be separate entries in the database. You can use the Configure Dictionary feature under the Tools menu to specify what fields you want to include in minor entries in the published dictionary.
Example (16) cannot be handled in this way because it is not really a variant. A variant is an alternate form of the same lexeme. But 'lift' and 'elevator' are different lexemes. The relation between them is actually more similar to that of synonyms, except that in this case one word is British and the other American. Another difference is that this kind of link can be between senses of a lexeme. In the case of 'lift' and 'elevator' each lexeme has other senses. Only one sense of each lexeme is involved in the variant relation. So rather than call these 'variants', we call them 'dialect synonyms'.
You have to handle dialect synonyms in the same way as you would regular synonyms using the Lexical Relations field on the sense level. You should create a new lexical relation in the Lists--Lexical Relations area. In the Reference set type field specify that it is an Entry/Sense Pair - 2 relation names. This allows you to give an abbreviation and reverse abbreviation for the cross-references in the two entries. If I was producing a dictionary in which British English was the primary dialect, I would give 'American dialect synonym' in the Name field, and give 'Am. var. of' as the Abbreviation. I would give 'British dialect synonym' as the Reverse Name and 'Am. var.' as the Reverse Abbreviation. Then in the entry for 'lift' in the Lexical Relations field I would select Insert British dialect synonym Relation (to this American dialect synonym) from the list of choices. In the Add Reference dialog box I would type 'elevator' in the Find box, click Choose a sense of the entry, then select the correct sense. The program will then add the appropriate cross-reference to the Dictionary view of each entry.
An inflected form is composed of a stem and one or more inflectional affixes. Consider the following set of words:
| (17) |
|
Each of them is a well-formed, natural English word that you might encounter in speech or in writing. If we were to make each one of them into a dictionary entry, we would have something like the following. (The words have been alphabetized and each one given a short definition.)
| (18) |
|
What is the problem with a dictionary like this? Most people would recognize that 'deeds' is the plural of 'deed'. In fact many people might say something like, “Deed and deeds are really the same word. Deeds is just the plural of deed.” (In lexicography we would say they are the same 'lexeme', but most people think of them as the same 'word'.) What they mean by this is that they don’t think of 'deed' and 'deeds' as two different words, but as two forms of the same underlying word (lexeme). Similarly most people think of 'does', 'doing', 'did', 'done' as forms of the word 'do'. Likewise 'redoes', 'redoing', 'redid', 'redone' are forms of 'redo'. However 'doable' has no alternate forms. It is all by itself.
Another problem is that a dictionary like the one above would be huge. Every verb in English potentially has five different forms (stem, past tense, past participle, present participle, third person singular present tense) and every noun has two forms (singular and plural). If we included all these forms, we would almost triple the size of the dictionary. To print such a book would be much more expensive.
This is a much greater problem for languages with many affixes. English only has five different verb forms, but some languages have thousands. It would be very expensive, if not impossible, to include every single possible word in the dictionary.
To solve these problems we must distinguish between a lexeme and all the inflected forms of the lexeme. Language explorer uses the terms 'word' and 'wordform' synonymously to refer to any well-formed, naturally occurring word, including all inflected forms. Each of the words in example () is a wordform. But to save space only the following are made into entries:
| (19) |
do, deed, doable, redo
|
Language Explorer keeps track of each wordform that it encounters in your text corpus and makes a list of them. This list is called the ‘wordform inventory’. The program does this automatically. There are three views of the wordform inventory in the Texts & Words-Word List Concordance, Word Analyses, and Bulk Edit Wordforms panes. Language Explorer also keeps a list of dictionary entries in the Lexicon pane. However you must tell the program which wordforms you want to make into dictionary entries. To see the difference in the two lists compare the following:
| (20) |
|
Although there are exceptions, most dictionaries do not include inflected forms as dictionary entries. Instead each inflected form is combined with the headword into a single entry. So each dictionary entry represents not just the headword, but all the inflected forms as well. You can think of the headword as the representative of all the inflected forms. In a language like English we can give the stem as the headword and leave out the inflected forms.
| (21) |
|
Sometimes we may want to give some of the inflected wordforms in the dictionary entry, especially if they are irregular or unpredictable. The English words 'did' and 'done' are irregular. So we could list the irregular inflected forms in the entry:
| (22) |
|
But in some languages all the forms of a word have inflectional affixes. In these languages the headword must be an inflected form. For instance the Swahili (a Bantu language spoken in Kenya and Tanzania) word 'mti' ‘tree’ is formed from the singular prefix 'm-' and the bound root 'ti'. The plural is 'miti'. So in the dictionary entry the headword is 'mti', an inflected word form:
| (23) |
|
In Swahili a word starting with the singular prefix 'm-' could have a plural 'miti' or 'bati'. So we need to indicate the plural form in the entry:
| (24) |
|
From these examples you can see that (1) the headword is just one of the wordforms, (2) we pick one wordform to represent the rest, (3) we may or may not list the other wordforms in the entry.
Consider the following irregularly inflected verbs:
| (25) |
|
| (26) |
|
In example (25) the third singular 'has' and past tense form 'had' are irregular. It might be possible to say that 'have' has an allomorph 'ha', and analyze 'has' and 'had' as 'ha-s' and 'ha-d'. But since no English verb ends in 'a', this analysis violates a rule. In addition the suffix '-ed' is spelled 'ed', not 'd', when it follows a vowel other than 'e' (e.g. 'soloed'). It is better to analyze 'has' and 'had' as single portmanteau morphemes (a single form with two components of meaning that are normally handled by separate morphemes) and gloss them as 'have.3S' and 'have.PST' respectively.
We handle this in Language Explorer in the Variants section of the Entry pane. An irregularly inflected form is not a variant. But since they are handled in a dictionary in similar ways, we handle them in Language Explorer together. Each irregularly inflected form should be added to the Variants section. In the Variant Type field you should choose the type of variant from the list. You can set up a new variant type in the Lists--Variant Types pane. For instance for irregular past tense verbs in English I would set up a new variant type and call it "Irregular Past Tense". I would give "irreg. past tense of" in the Abbreviation field and "irreg. past tense" in the Reverse Abbr. field. Language Explorer will automatically create a new entry for each irregularly inflected form. It will also create a minor entry for each one in the Dictionary view. (You can change this display feature if you want.) The parser will also treat irregularly inflected forms such as 'has' and 'had' as single morphemes and gloss them correctly. However the gloss will be taken from the entry for the irregularly inflected form, not from the primary entry. This is not ideal, but is the way Language Explorer currently works.
In example (26) the past tense 'went' is not only irregular, it is based on a different root. The technical term for this is 'suppletion'. Historically we know that 'went' was the past tense of 'wend'. Today the past tense of 'wend' is 'wended', and 'went' is used as the past tense of 'go'. In Language Explorer we handle this in the same way as other irregularly inflected forms by adding 'went' in the Variants section of the entry for 'go'. Language Explorer automatically creates a separate entry for 'went'. In the entry for 'went' you can give a gloss or provide other information such as the etymology.
There are three primary reasons why Language Explorer creates a separate entry for variants and irregularly inflected forms. The first is that it is difficult to get the parser to analyze them correctly in any other way. The second is that we often want to create a minor entry for them in a published dictionary. The third is that we often need to record other information about them such as pronunciation, variants, etymology, usage, example sentences, etc. Even though variants and irregularly inflected forms are not separate lexemes, for these practical reasons it is best to handle them in separate entries in the database.
A complex form is a lexeme composed of two or more morphemes. Consider the following set of words:
| (27) |
|
We recognize that each of them is based on the word 'peace'. For instance 'pacification' is a combination of 'peace' and the derivational affixes '–ify', '-ic', and '-ation'. The word 'peacetime' is composed of the words 'peace' and 'time'. The phrase 'make peace' is a combination of the words 'make' and 'peace'. But 'peace' itself is not based on any other word and cannot be divided into morphemes.
The technical term for a word that is not based on any other word and cannot be divided into morphemes is 'root'. The word 'peace' is a root. A complex form must contain at least one root.
The technical term for a word composed of a root and one or more derivational affixes is 'derivative'. The words 'peaceful', 'pacify', 'pacifist', 'pacification', and 'Pacific' are derivatives.
The technical term for a word composed of two or more roots (or stems) is 'compound'. The words 'peacetime', 'peace-keeping', and 'peace-loving' are compounds. Notice that the hyphen is used in the English orthography to divide some compounds but not others.
The technical term for a lexeme composed of two or more words is 'lexical phrase' (or sometimes 'phrasal lexeme'). The phrases 'peace treaty', 'keep the peace', and 'be at peace with' are lexical phrases. So there are three basic kinds of complex forms—derivative, compound, and lexical phrase. You will also see the technical term 'multiword expression', often abbreviated MWE. But this is a more general term for any construction composed of two or more words, including lexical phrases, greetings, proverbs, and common collocates.
Notice that there is a mismatch between the category 'stem' and the category 'complex form'. A complex form can be a derivative, compound, or phrase. The category stem is limited to single words.
A contraction is a combination of two lexemes, each of which maintains its own meaning. For instance 'hasn't'' is a combination of 'has' and 'not'.
Contractions are different from compounds. A compound, such as 'hasbeen', is a combination of two lexemes with an unpredictable change in meaning. There is no such change in meaning in a contraction.
Contractions are different from clitics. A clitic is a lexeme that is grammatically independent but attaches phonologically to any adjacent word. An example of a clitic is the English possessive –’s in the phrases 'Elizabeth's hat', 'the queen’s hat', and 'the queen of England's hat'. The clitic –'s obligatorily attaches to whatever noun precedes it. In contrast a contraction is a specific pair of words that regularly combines. The combination may be obligatory, as in the case of 'let's', as in "Let's go" ("Let us go" has a different meaning), or it may be optional, as in the case of 'we've', as in "We've been honored," or "We have been honored."
Contractions are different from portmanteau morphemes. A portmanteau morpheme is a single, indivisible morpheme that combines two meanings that are usually expressed by separate morphemes. An example of a portmanteau morpheme is the word 'were' which is a single morpheme expressing the meaning of the lexeme 'be' and the grammatical category 'Past.tense'. 'Were' cannot be divided into two morphemes. (Note that 'busted' can be divided into bust-ed 'bust-Past.tense'.) In contrast the contraction 'we're' (we are) can be divided into 'we-'re'.
One or both members of a contraction can be shortened. Most English contractions only shorten the second member, as in 'I'm' (I am), 'it's' (it is), 'isn't' (is not). Others shorten both members, as in 'won't' (will not), 'shan't' (shall not), 'ain't' (am not).
A contraction can combine more than two members, as in 'wouldn't've' (would not have).
English orthography uses the apostrophe to indicate the loss of a phoneme, as in 'shouldn't' (should not). But when both words lose a phoneme, only one apostrophe is used, as in 'shan't' (shall not). In writing sometimes a contraction is written out as two separate words, even when it would normally be shortened to the contracted form in speech. Other languages may or may not choose to follow these orthographic conventions.
Two lexemes are 'homonyms' if they have the same form, but are unrelated in meaning. Consider the following two dictionary entries:
| (29) |
|
| (30) |
|
The first meaning of 'bear' comes from an old root meaning 'brown'. The second entry has three meanings, all of which come from an old root meaning 'carry'. Since all three meanings of the second entry are related and come from the same root, we put them together in the same entry. But since 'bear' (large mammal) and 'bear' (carry) are unrelated in meaning, we keep them separate. In Language Explorer you would create separate entries in the lexicon for 'bear' (large mammal) and 'bear' (carry). You would create three senses in the entry for 'bear' (carry), one for each meaning. The program automatically supplies the homonym numbers and sense numbers.
There are two kinds of homonyms. If two words are spelled the same, we call them homographs. If two words are pronounced the same, we call them homophones. 'Bear' (large mammal) and 'bear' (carry) are both homographs and homophones, since they are spelled and pronounced the same. The English words 'sow' [so] 'to plant seeds' and 'sow' [saw] 'female pig' are homographs, but not homophones, since they are spelled the same, but pronounced differently. The words 'sow' [so] 'to plant seeds' and 'sew' [so] 'to join pieces of cloth using needle and thread' are homophones, but not homographs, since they are pronounced the same, but spelled differently. You should create separate entries for both kinds of homonyms.
Some dictionaries do not distinguish homonyms and choose instead to combine them in a single entry. The reason for doing this is that most users are not aware of the etymology of words and therefore do not understand the reason for separating a single form such as 'bear' into two entries. They would rather just search a single entry for the meaning that they are interested in. It is also sometimes hard for a lexicographer to distinguish homonyms without doing a lot of careful historical research. You are free to separate homonyms into separate entries or combine them in a single entry. There are three primary reasons for separating homonyms. The first is that dictionaries have traditionally separated them and users may expect all the senses in an entry to be somehow related. The second reason is so that you can provide etymological information for each. The third reason is so that you can provide information that may be different between the two homonyms. For instance English dictionaries indicate the inflected forms of irregular verbs. Sometimes homonyms belong in two different inflection classes and you have to create two entries so that you can indicate how each is inflected:
| (31) |
|
| (32) |
|
We have been discussing relations between lexical forms. But some lexemes are related not by form but by meaning. These meaning-based relationships are called "lexical relations."
Some lexicographers wish to indicate all the lexical relations that exist in the lexicon. Such a task would be enormous, since the entire lexicon is related in a giant web of relationships. These relationships are of many types. Some are regular and easy to understand, while others are very complex and unique. Lexicographers have developed lists of some of the more regular and frequent lexical relations. We do not have space here to describe them all. The following are a few of the most commonly used lexical relations:
You can add to the list of lexical relations in the Lists--Lexical Relations pane. So you can customize the list to suit your needs.
The Lexical Relations field was designed to enable you to link two entries (or particular senses of two entries) and choose the particular lexical relation that exists between them. Go to one of the entries and find the relevant sense. Click the Lexical Relations field and then click the blue arrow on the left of the line. Select the appropriate lexical relation from the list. Then in the Add Reference dialog box select the sense of the other entry.
You can create a link between two senses from either entry. You only need to create the link once. You don't have to do it in both entries. Language Explorer automatically creates a cross-reference in each entry in Dictionary View.
Since you are relating meanings, you should link the relevant sense of one entry to the relevant sense of the other entry. You will find that many words have other meanings that will not be relevant to the lexical relation. So I recommend that you always specify the sense of the other entry. For instance the noun 'tool' is related to the noun 'hammer' by the generic:specific lexical relation. But both 'tool' and 'hammer' have other meanings as nouns and both can be used as verbs. So only one sense of 'tool' and one sense of 'hammer' are related by the generic:specific lexical relation.
If you wish to create a cross-reference between two lexemes on the entry level, you can use the Cross References field. However you should use caution when using the Cross References field. If two entries are related on the entry level, they are most likely related in form, one being a complex form and the other a root. In such cases you should link them using the Complex Forms field. If two entries are not related by form, but by meaning, it is better to use the Lexical Relations field to link the relevant senses.
Both the Lexical Relations field and the Cross References field create a link between two entries (or senses). This ensures that both entries exist and that the spelling of the headword and reference are the same. You can also refer to another entry from within a field. For instance you could use a vernacular word in a definition. However such a reference is not a link, so there is no guarantee that the other entry exists or that the headword of the other entry is spelled the same as the reference. So whenever possible you should use the Lexical Relations field.
Understanding the following distinctions will help you understand how Language Explorer functions.
Words are composed of morphemes. A morpheme can be a root or an affix. Affixes like -s cannot stand alone as an independent word, but roots like 'dog' can. So a word can consist of a single root. An affix is never a word. (A clitic is a special kind of morpheme that acts like a word syntactically, but like an affix morphologically and phonologically. An example of a clitic is the form of the verb 'be' in 'I'm'.) When we parse words, we divide them into morphemes. Inflected words are composed of morphemes. They are composed of a stem and at least one inflectional affix. Derivatives, compounds, and phrases are also composed of morphemes. Derivatives are words composed of a root and at least one derivational affix. Compounds are words composed of at least two roots and sometimes one or more derivational affixes. Phrases are composed of two or more words. So the terms 'word' and 'morpheme' do not refer to the same set of things:
The terms 'lexeme' and 'entry' both refer to the same basic thing, except that a lexeme is a unit in the mental lexicon and an entry is a unit in a database or published dictionary. Both refer to the abstract unit underlying a set of inflected forms such as 'stop', 'stops', 'stopping', 'stopped'. This abstract unit is a combination of a phonological form, a set of grammatical rules governing its use, and one or more meanings. There are a few differences between them. A lexeme only contains information that a person has in his mind. An entry in a database may contain other information such as the etymology of the word.
Some lexicographers use the term 'lexeme' to refer to the combination of a form and a single meaning. In the literature on lexicography you will sometimes encounter other terms that refer to the same basic unit as a lexeme or entry. An entry in a database is sometimes called a 'lexical entry' to distinguish it from entries in other kinds of databases. The general term for an entry in a database is 'record'. (Each part of a record is called a 'field'.) An entry in a published dictionary is sometimes called an 'article'. We also talk about 'main entries', 'subentries', and 'minor entries' in a dictionary. Since the term 'entry' is used for both an entry in the database and an article in the dictionary, Language Explorer follows this tradition and uses 'entry' for both.
A problem sometimes occurs in inflected languages when the stem of a word never occurs by itself in speech. Consider the following inflected forms of the Koine Greek bound stem 'dō' (δω) 'give':
| (34) |
|
The problem with 'dō' is that it never occurs by itself. It is always inflected (although the infinitive δῷ is very close to δω). The first form 'didōmi' (δίδωμι) is the present tense first person singular. The root is 'dō', 'di-' is an inflectional prefix meaning 'Present', and '-mi' is an inflectional suffix meaning '1st person singular'.
We need to choose some form of 'dō' as the headword in the entry. But experience has shown that people usually have trouble finding the root of a word if it never occurs by itself. So it is best to pick a form of the word that actually occurs in speech. Therefore the bound form 'dō' is not a good choice. Greek dictionaries traditionally use the present tense first person singular form of verbs as the headword. So 'dō' would be listed under 'didōmi' rather than 'dō'. This is called the citation form. The citation form is that form of a word that is used to begin the dictionary article. A traditional dictionary is organized by alphabetizing the citation forms. The uninflected stem is called the lexeme form. In our example 'dō' is the lexeme form and 'didōmi' is the citation form.
But there is a problem. Each of the forms of 'dō' listed above would alphabetize in a different place. If someone looked up 'edōka', he would look for it in the 'E' section and wouldn't find it. So he has to know what form the word is listed under. The important principle is to remember that people have to find the entry. Whatever form we pick as the citation form, people have to be able to find it. If someone wants to find the entry for 'edōka', where will he look? You need to test your users to determine if they can find the entry for a word. Sometimes children are taught in school how to use a dictionary. But if you are publishing the first dictionary in your language, this may not help. The strategy for finding a word in one language will be different from the strategy required for another language.
In a language like Greek some words are inflected and others are not. In the previous section we saw that the bound stem (lexeme form) 'dō' is not used as the headword in a published dictionary. Instead an inflected form 'didōmi' is used. In contrast the Greek word 'kai' 'and' is not inflected. The lexeme form is 'kai' and it is used as the headword. So in some situations the (uninflected) lexeme form is used as the headword and in other situations the (inflected) citation form is used as the headword. So the terms citation form and headword are not exactly synonymous.
In Language Explorer there is a field for the lexeme form and a second field for the citation form. You would only use the Citation Form field when it is needed. If your language does not have inflectional affixes, you would not need to use the Citation Form field because the lexeme form can always be used as the headword. In many languages such as Greek, sometimes the lexeme form can be used as the headword and sometimes the citation form is used. If the lexeme form is used as the headword, you can leave the Citation Form field blank.
Some lexicographers only want to use the Citation Form field when it is different from the Lexeme Form field. If the two are the same, they want to leave the Citation Form field empty. The reason for this is so that changes to the spelling of the lexeme only have to be made once. Other lexicographers prefer to fill in the Citation Form field for each entry. This makes it possible to sort or filter the Citation Form field. The choice is up to you.
In browse view you often want to sort on the headword. Language Explorer displays a "virtual" Headword field in the browse views to enable you to sort on the headword. If there is something in the Citation Form field, it is used as the headword. Otherwise the contents of the Lexeme Form field is used. You cannot edit the Headword field, since it is a virtual field. If you want to edit the headword, you must edit the Citation Form field or the Lexeme Form field. Language Explorer generates the headword in Dictionary view in the same way, by using the contents of the Citation Form field or, if there is nothing in the Citation Form field, by using the contents of the Lexeme Form field. The following screen shot shows three entries. In the first and third entries the Headword is taken from the Citation Form field. In the middle entry, which has nothing in the Citation Form field, the Headword is taken from the Lexeme Form field.
Consider the following two sets of words:
Both sets represent the inflected forms of the first word in the set. But notice that 'pressurize' is a derivative of 'press'. When we talk about inflected forms, we want to be able to distinguish between an inflected form and an uninflected form. The technical term for an uninflected form is 'stem'. So in our examples both 'press' and 'pressurize' are stems. 'Press' is an underived stem and 'pressurize' is a derived stem.
Similarly, when we talk about derived forms, we want to be able to distinguish between a derived form and an underived form. The technical term for an underived form is 'root'. A stem is a form without any inflectional affixes. A root is a form without any derivational affixes. In our examples only 'press' is a root. So 'press' is both a root and a stem. In contrast 'pressurize' is a stem, but not a root. We would say that 'pressurize' is the stem of 'pressurized'. We would say that 'press' is the root of 'pressurize'.
A stem can be a root, derivative, or compound.
If a stem can occur by itself as a full word, we call it an 'unbound stem'. If it must occur with an affix, we call it a 'bound stem'. This is parallel to bound and unbound roots.
English has very few roots that cannot also be words. The root 'pant' (noun) is one. It occurs in the plural form 'pants' and in some compound words such as 'pant leg' (written as two words) and 'pantdress'. But it never occurs by itself as a word. So 'pant' is a bound root. This shows that the terms 'root' and 'word' do not mean the same thing. A root is a part of a word. A root can be a word, but isn't necessarily. A root that cannot be a word is called a bound root. A root that can be a word is called an unbound root.
Language Explorer needs to know which entries are roots and which are stems in order to parse words correctly. You indicate this in the Morph Type field.
Dictionary makers over the years have developed a tradition of four types of entries for published dictionaries--main entry, subentry, minor entry, and minor subentry[7]. We will discuss each of these and what they are normally used for. We will also discuss various ways in which lexeme forms can be cross-referenced.
The reason why we need different kinds of entries is that there are different kinds of lexemes and various kinds of forms. We have seen that there are several types of lexemes—morphemes such as roots and affixes, and complex forms such as derivatives, compounds, and lexical phrases. In addition some morphemes have allomorphs, some lexemes have variants, and some lexemes have irregularly inflected forms. All of these need to be entered in the lexicon in some way. Each kind of form is related to other forms in a variety of ways. (For instance a compound is composed of two or more roots.) There are various ways of entering forms into the lexicon, various ways to indicate how they are related, and various ways of presenting them in a published dictionary.
The primary way to enter a form into the lexicon is to create an entry for it. However not all forms require a separate entry. Language Explorer requires you to create entries for all lexemes (morphemes and complex forms). You enter variants and irregularly inflected forms in the Variants section of the primary entry. Language Explorer automatically creates a separate entry for variants and irregularly inflected forms in case you need to give additional information about their meaning or usage. Allomorphs are entered in the Allomorphs section of the primary entry. Regularly inflected forms are usually ignored in a dictionary, but are sometimes entered in a custom field.
Language Explorer makes some assumptions about how each type of form should be handled in a printed dictionary. The first major assumption is that forms fall into three major groups--morphemes, complex forms, and variant forms (including irregularly inflected forms). These three groups are handled differently as we will see.
In this discussion we must keep one point firmly in mind. A computer can record data in one format and print (or otherwise export) the same data in another format. So we must distinguish between the way we enter data, and the way the data will be presented in print. Language Explorer requires that each morpheme, complex form, and variant be a separate entry in the database. However the program allows entries to be printed in various ways. Just because a form is entered into the database in one way does not mean it must be printed the same way. In this section we will discuss the ways in which data must be entered and the ways in which it can be printed. You can choose how a particular type of entry will be presented in Dictionary view. Morphemes are always presented as main entries. You can set up different kinds of complex forms in the Lists--Complex Form Types area. You can set up different kinds of variants in the Lists--Variant Types area. You specify how an entry is formatted by going to the Lexicon area and using the Configure Dictionary tool under the Tools menu. For more on data versus presentation see section 2.2.3.
The term 'main entry' refers to a type of entry in a printed dictionary. An entry in a computer database is sometimes called a 'record', but in Language Explorer it is called an 'entry'. We must carefully distinguish between an 'entry' in the database and a 'main entry' in a printed dictionary. The two are not necessarily the same. A main entry is a normal full entry for a lexeme. A main entry alphabetizes under its headword.
In Language Explorer roots are entered in the database as entries. They are always presented in a printed dictionary as main entries. If affixes are included in the dictionary, they are also entered as entries and presented as main entries. The following example shows how the root 'man' would be presented as a main entry:
| (39) |
|
Complex forms are also entered in the database as entries. They can be printed as main entries, but as we will see below, they can also be printed as subentries. Variants and irregularly inflected forms are usually not printed as main entries, but in certain cases can be. The following example shows how the idiom 'make peace' would be presented as a main entry:
| (40) |
|
A subentry is a kind of entry in a printed dictionary. It is a normal full entry that is subordinated under a main entry and indented. Subentries are used for complex forms in order to physically place them with the root (or roots) that they are composed of. For instance in the example below 'make peace' has been subordinated as a subentry under the entry for 'peace'. Otherwise it would alphabetize under 'M'.
| (41) |
|
A root dictionary is composed of main entries for each root with all complex forms presented as subentries under their roots. If you wish to create a root dictionary, you would create entries in the database for each root and complex form, but present each complex form as a subentry under the root. Some language families, most notably Afro-Asiatic, have a tradition of making root dictionaries. For more on root dictionaries see section 3.5.2.
You can configure your dictionary as a root dictionary using the Configure Dictionary tool in the Tools menu. If you choose the Root-based option in the Choose dictionary view to configure box, all the complex forms in your database will be formatted as subentries and placed under their root (or roots).
A minor entry is a type of entry in a printed dictionary. It is a short entry used to help the user find a main entry. Minor entries are used for variants and irregularly inflected forms. They can also be used for complex forms in a root dictionary. If the user is not familiar with the language, he may not know where to find a form. For instance he might not know that men is the plural of man. If he looks under men, he will not find the entry he is looking for unless you put in a minor entry for men. The following is a minor entry for men that directs the user to the entry man where he will find a description of man and its plural men.
| (42) |
|
The corresponding main entry (repeated from example (39) above) would be:
| (43) |
|
The following example is a minor entry for the British spelling variant colour. You would put such an entry in a dictionary of American English.
| (44) |
|
The corresponding main entry would be:
| (45) |
|
Minor entries are also used in a root dictionary for complex forms that have been placed under their roots. The following is a minor entry for make peace.
| (46) |
|
The minor entry directs the user to the main entries make and peace where he will find subentries for make peace. The corresponding main entries would be:
| (47) |
|
| (48) |
|
In Dictionary view you have the option of presenting an entry as a minor entry. To do this you would create an entry for a form, such as a variant, and leave the entry empty except for the Lexeme Form field, the Variant Type field, and the Variant of field. Language Explorer will then present the entry as a minor entry and also generates a cross-reference at the beginning of the basic/root entry. (If you want to, you can fill in other fields in the entry for the variant. If you do so, they will also be printed, effectively turning the minor entry into a main entry.)
A minor subentry is a type of entry in a printed dictionary. It is a short entry that is placed under a main entry and indented slightly. A minor subentry serves as a cross-reference to direct the user to a different main entry where the lexeme is described. Minor subentries can be used for complex forms in a lexeme dictionary. The following example is a minor subentry for make peace:
| (49) |
|
The minor subentry directs the user to the following main entry for make peace:
| (50) |
|
Currently Language Explorer allows minor subentries in the Hybrid view. Currently Language Explorer also generates cross-references at the end of the main entry.
In a root dictionary a compound or idiom can be a subentry under more than one root. To save space in a printed dictionary, you could make the compound or idiom into a full subentry under one root and a minor subentry under the others. The following examples show make peace as a minor subentry under make and a full subentry under peace:
| (51) |
|
| (52) |
|
The options in Dictionary view do not currently include presenting an entry as a minor subentry under one root and a full subentry under another as in the previous two examples.
Cross-references to related forms are traditionally placed either immediately after the headword at the beginning of an entry, or at the end of the entry. Cross-references for variants and irregularly inflected forms are usually placed at the beginning of the entry. Often there is no extra information given for the variant. In the following examples there is no information given about colour except that it is the British spelling variant of color. In the first entry there is a cross-reference at the beginning of the entry to colour. The second entry is a minor entry which serves as a cross-reference back to color.
| (53) |
|
| (54) |
|
This is the normal way of handling variants and irregularly inflected forms. The basic form is presented as a main entry. The variant is noted as a cross-reference at the beginning of the entry and also presented as a minor entry. This is perfectly acceptable practice as long as one form is more basic than the other and as long as there is no need to describe the difference between the variants.
However there are situations in which both forms should be treated equally. For instance you might want to treat both the American and British dialects of English equally. In this case neither color nor colour is basic. So both are presented as main entries with a cross-reference to the other form at the beginning of each entry:
| (55) |
|
| (56) |
|
Dictionary view has the option of presenting variants either way. Both forms are entered in the database in separate entries and are linked as variants. You can determine how much information you want in each entry. You can also specify how the variants are introduced (e.g. "Am. sp. var. of") in the Lists-Variant Types area.
Some lexicographers prefer to list complex forms at the end of the entry for the root within the paragraph for the main entry rather than as a minor subentry on a new line. This saves space. In the following example there would be corresponding main entries for make peace and keep the peace. The cross-references direct the user to these main entries where the complex forms are described.
| (57) |
|
If you choose Lexeme-based in Configure Dictionary, Language Explorer can generate a cross-reference for each complex form. To display these you need to check Referenced Complex Forms at the bottom of the list of fields.
Language Explorer is designed to enable you to maintain one lexical database, but produce more than one type of dictionary.
Some lexicographers want to produce a dictionary that only includes morphemes (roots and affixes). Such a dictionary is sufficient for limited purposes, such as parsing isolated words down to the root level. However, except for such restricted uses, a morpheme dictionary is not a practical tool. For one thing, non-linguists can seldom use a root dictionary. The mind buries abstract representations deep in the subconscious. The only things that are easily accessible to most people are ‘words’. So practical dictionaries are almost always stem dictionaries. Otherwise they run the risk of being difficult or impossible to use for most people (and usually are).
Most of us need to produce lexeme dictionaries (also known as stem dictionaries). By this I mean the entries include roots, affixes, derivatives, compounds, and lexical phrases. Even isolating languages have lexical phrases.
There are two ways to arrange entries in an alphabetically organized dictionary—by root or by lexeme. A root dictionary places all derivatives, compounds, and phrases under their respective root (or roots) and formats them as subentries. A lexeme dictionary alphabetizes all the complex forms separately as main entries. In a root dictionary the three entries ‘do’ ‘doable’ ‘redo’ would be organized like this:
| (58) |
|
The same three entries in a lexeme dictionary would be organized like this:
—D—
| (59) |
|
| (60) |
|
—R—
| (61) |
|
Notice that complex forms that are derived by suffix will alphabetize near each other, but those that are derived by prefix will alphabetize elsewhere. So if your language only has derivational suffixes, the difference between a root dictionary and a lexeme dictionary will be small. But if your language has lots of derivational prefixes, the difference will be very great. Derivational prefixes scatter the derivatives throughout a lexeme dictionary.
Language Explorer allows you to format and display the database as a root-based dictionary or lexeme-based dictionary in Dictionary view. It also includes a third format called Hybrid view. In this view, complex forms appear separately as main entries, but there is also a minor subentry for them under their root. You can also export the database in any of these formats just by changing the configuration--it is not necessary to change the organization of the data.
Most dictionaries are neither completely root nor lexeme dictionaries, but a combination of the two. The reason for this is that there are advantages and disadvantages to each type. So most lexicographers choose some sort of compromise.
The most serious disadvantage of a root dictionary is that the entries are hard to find, especially for someone who does not know the language well. For someone who is not familiar with English the words 'redo' and 'redolent' look similar. But 'redo' is derived from 'do' and would be a subentry under 'do'. On the other hand 'redolent' is borrowed from French and is based on the same root as 'odor' and 'olfactory'. Oddly enough the derivational prefix 're-/red-' ('re-do' and 'red-ol-ent') is the same in the two words, but hardly anyone except a historical linguist would know this. So almost no one would know to look for 'redolent' under a root 'od' or 'ol'.
The greatest advantage of a root dictionary is that the user can see at a glance all the complex forms based on the root. He can compare them and see semantic similarities.
One compromise that is sometimes taken is to make all complex forms into main entries, but also list them as cross-references at the end of the root entry:
| (62) |
|
Some language families, such as Afro-Asiatic, have a tradition of root dictionaries. However you should test your intended users to see if they can find entries in a root dictionary.
Some lexicographers want to produce a dictionary of single words. There are two types of word dictionaries. The first type lists all fully formed words, including inflected forms. The second type only lists stems (perhaps using an inflected form as the citation form). A spelling dictionary can be of either type.
The problem with word dictionaries is that about one third of the lexemes in a language are lexical phrases. Some lexicographers produce a word dictionary, but list the lexical phrases at the end of the entry for the root. Sometimes they include a definition of the phrase. Such a dictionary is something between a root dictionary and a lexeme dictionary. (In fact it would be accurate to call it a lexeme dictionary.) Language Explorer enables you to produce such a dictionary. To do this, you need to click the Exclude As Headword field in each entry that is a phrase.
Language Explorer enables you to produce either a monolingual or bilingual dictionary. A monolingual dictionary uses the vernacular language to describe the words. For instance a monolingual Swahili dictionary is a list of Swahili words with definitions (and other parts of the description) in Swahili. In contrast a bilingual dictionary is a list of vernacular words, but the description is in a second language. For instance a Swahili-English bilingual dictionary would contain a list of Swahili words, but the description would be in English. An English-Swahili dictionary would be a list of English words with the description in Swahili.
Sometimes dictionary publishers will combine a Swahili-English and English-Swahili dictionary in one volume. You can produce such a dictionary with FieldWorks, but unfortunately you cannot do so in a single project. You must set up one project for the Swahili-English dictionary and a second project for the English-Swahili dictionary. This makes it difficult to coordinate the two halves.
Producing a double Swahili-English, English-Swahili dictionary really involves producing two separate dictionaries. The first requires you to describe all the words of Swahili; the second requires you to describe all the words of English. Most dictionary projects for minority languages do not have the resources to produce both. So many projects choose to produce a single Swahili-English dictionary with an index of English words. In such a dictionary the first language is called the vernacular language and the second language is called the analysis language. In a monolingual dictionary the vernacular and analysis languages are the same. In a Swahili-English dictionary the vernacular language is Swahili and the analysis language is English.
Language Explorer currently supports monolingual and bilingual dictionaries. It also allows you to set up more than one analysis language. For instance, if you want to produce a dictionary for Swahili, the vernacular language is Swahili. But you can set up Swahili, English, French, and Portuguese as analysis languages. This makes it possible to export the database as a monolingual Swahili dictionary, a Swahili-English bilingual dictionary, a Swahili-French bilingual dictionary, or a Swahili-Portuguese bilingual dictionary. You could even export the database as a multilingual dictionary with the definitions in Swahili, English, French, and Portuguese. So Language Explorer is designed to enable you to maintain a single database for multiple purposes.
If you do not have the resources to produce a double Swahili-English, English-Swahili dictionary, you can produce a single Swahili-English dictionary and an index of English words. Such an index is merely a list of English words indicating the equivalent Swahili entry. In other words it helps the user find a Swahili entry. An index like this is sometimes called a 'finder list'. In Language Explorer it is called a 'reversal index'. Language Explorer enables you to produce a reversal index for each analysis language. So for our Swahili dictionary we could produce an English index, a French index, and a Portuguese index. You create reversal index entries in the Reversal Entries field. Since a word can have different meanings and each meaning may have a different translation equivalent in the analysis language, the Reversal Entries field is a sense level field. So you create a reversal entry for each sense of an entry in the lexicon. The Reversal Indexes view enables you to see what the index will look like and to edit individual reversal entries. The Bulk Edit Reversal Entries area enables you to use the bulk edit tools to edit large numbers of reversal entries at once.
Language Explorer is designed to help you handle minor dialectal differences. However it is not designed to handle dialects that are quite different. If your language has multiple dialects, you can indicate differences between them as long as there aren't too many differences and the differences are not very complicated. However if there are many differences, especially if there are many dialects, you will have difficulty keeping track of all the differences. Your dictionary will quickly fill up with minor entries and cross-references.
If you have multiple dialects, you need to pick one as the primary dialect. Sometimes for political reasons all dialects have to be treated evenly in a published dictionary. It is possible to print your dictionary as if all dialects are equal. But Language Explorer requires you to enter your data as if one dialect was primary. Even if all your dialects are equal in size and prestige, you still need to pick one as the primary dialect because of the way Language Explorer handles dialects. The reason for this is that it assumes that one entry will be the main entry and other dialectal forms will be handled in minor entries. You can duplicate all the information from the main entry in the minor entry and make it look like the two entries are equal. But Language Explorer still treats one entry as the main entry. The reason is that duplicating an entry each time there is a difference in the dialects would quickly increase the size of the dictionary. So traditionally dictionaries have picked one dialect as primary and handled dialectal variants with small minor entries. Language Explorer was designed to support this tradition.
Regular differences in pronunciation between dialects should be described in the introduction to the dictionary or in the Grammar Sketch. These regular differences should be ignored in the dictionary entries. If a dialectal variant is different from the basic form in spelling, you should enter the variant in the Variants section. If a dialectal variant is the same as the basic form in spelling, but irregular in pronunciation, you should create a separate pronunciation for it in the Pronunciation field and indicate the dialect in the Location field. If two dialects use two different lexemes for the same sense, you should link the relevant senses of the two entries using the Lexical Relations field. You should set up a lexical relations type for each dialect. You do this in the Lists-Lexical Relations area.
Dictionaries often indicate differences in spelling and pronunciation between dialects. But dialects do not just differ in form. A lexeme can vary in any aspect of its form, grammar, meaning, or function. There may be differences in grammatical category, inflection potential, and syntactic restrictions. Different dialects may require different definitions. There may be differences in sociolinguistic usage. Dialects may differ in how a word is spelled or pronounced. But they may also use different lexemes for the same meaning (e.g. British lift and American elevator). Some dialects have a lexeme, but there is no equivalent lexeme in the other dialects. For instance the Australian word joey means 'baby kangaroo'. But there is no equivalent word in American English. We have to use a descriptive phrase, such as 'a baby kangaroo' or 'the kangaroo's baby', when we want to talk about it. So one of the challenges in handling multiple dialects is to identify all the differences between the dialects and developing ways to indicate the differences. Currently there is no mechanism in Language Explorer to indicate which fields apply to which dialects. For instance there is no way to indicate that an example sentence is in one of the dialects. This makes it very difficult to describe dialectal differences other than differences in form.
If you have dialects that are very different, you may find that the number of differences is so large that it is very difficult to handle them all. This can also be a problem if you are trying to handle many dialects in a single dictionary. With major differences and multiple dialects the complexity will increase exponentially. You may find that your dictionary becomes cluttered with lots of notes on dialectal differences, lots of minor entries for variants, and lots of cross-references. If this is the case, you may want to limit your dictionary to a single dialect. There may be political reasons why you have to handle multiple dialects in a single dictionary. But this may cause serious problems for you. It might be better to create separate dictionaries for each dialect. To do so in Language Explorer means setting up more than one project. Language Explorer does not have the capability of cross-referencing two projects. So it is very difficult to simultaneously manage multiple projects for multiple dialects.
Some lexicographers want to set up one project to handle multiple dialects, but export the data in order to produce a separate dictionary for each dialect. This is very difficult to do in Language Explorer. It is possible to set up a custom field in which you indicate which dialects use each entry. For instance the entry for joey could be marked as Australian. It would be possible to filter the database for each dialect and only export those entries that are marked for a particular dialect. However some entries have senses that are limited to one dialect. For instance the meaning for lift 'a machine for moving people and freight between the floors of a building' is used in British English but not in American English. However other senses of the word are shared by both dialects. It is not currently possible to filter out senses when exporting the dictionary. Instead you would have to create two entries for lift, one for the British dialect and one for the American. However I'm not even sure this would work. Instead Language Explorer would need the ability to save multiple configurations in the Configure Dictionary tool, and to exclude senses (and fields) from a particular configuration.
For some purposes, such as machine translation, it is necessary to indicate correspondences between dialects or related languages. You can do this in Language Explorer by setting up each dialect as an analysis language and then providing a gloss for each dialect. Alternatively you can set up custom fields to handle the correspondences.
As with any project in Language Explorer, you have to decide what language or languages to use as the analysis language. If you are producing a monolingual dictionary, you will most likely have to choose one dialect as the analysis language. It is simply not practical to use each dialect as an analysis language when you have several dialects.
In summary, Language Explorer can handle multiple dialects if the dialects are close and if the differences are mostly limited to spelling and pronunciation. If there are many differences and if the differences include grammar, semantics, and pragmatics, it would be best to handle the dialects in separate projects.
Many of the words in a language have more than one meaning. This is especially true of the common words. Language Explorer enables you to create a separate sense for each meaning of a word. Each entry already has a section for the primary sense of the entry. The section begins with the label Sense 1. You can add a section for another sense by clicking anywhere on this line and then clicking Insert Sense. Language Explorer creates another sense section and labels it Sense 2. All the sense level fields are duplicated for each sense section.
Language Explorer automatically numbers each sense. However some lexicographers prefer to subordinate some senses under others. Consider the following entry:
| (63) |
|
The first three senses are about physical movement. The first one is very general in meaning and the next two are specific types of upward movement. The fourth and fifth senses are metaphorical and are actually referring to a change. They depend on the conceptual metaphor, "More is up, less is down." Sense 5 can be considered a specific application of the more general meaning in sense 4. The last sense does not involve movement or change. So instead of merely listing the senses, we could group them as follows:
| (64) |
|
Language Explorer allows you to do this. If you click anywhere on the first line of a sense (the line that says Sense 2), a small blue down arrow will appear on the left side of the line. If you click the blue arrow, you will get a menu of options. You can also get the menu by right clicking on the line. This menu doesn't have a name, but I'll call it the Sense menu. It has a number of useful options for managing the senses of an entry. The Demote option subordinates one sense under another. To change example (63) into example (64), I demoted senses 2, 3, and 5. To reverse this process, you can use the Promote option.
You can also reorder senses. For instance you might want to make sense 4 in example (63) the first sense because it is the most frequently used meaning. To reorder senses, choose Move Sense Up or Move Sense Down from the Sense menu.
You can merge two senses using the Merge Sense into... option from the Sense menu. For instance if you call up the Sense menu from the Sense 2 line and choose Merge Sense into..., you will get the Merge Sense dialog box. This displays the definitions from each of the senses in the entry. You would then pick one of the definitions and click Merge. For instance if you pick the first definition, sense 2 will be merged into sense 1. Sense 2 will be deleted and the contents of each field from sense 2 will be added to the end of the respective field in sense 1.
The Move Sense to a New Entry option enables you to split an entry. It will create a new entry with the same entry level fields and move the sense into the new entry. This option is especially useful when you find that an entry has two unrelated senses and you want to split the entry into homonyms.
Many lexemes have more than one sense and sometimes those senses belong to more than one grammatical category. Language Explorer requires you to give the grammatical category of each sense. The reason for this is because the interlinearizer and parser link wordforms to a particular sense of an entry and need to know the grammatical category of that sense. Because some dictionaries intermix senses with different grammatical categories, each sense must be given a grammatical category to eliminate possible confusion.
Various dictionaries use different systems to handle lexemes that belong to more than one grammatical category. The following examples illustrate some of the options and which ones are possible in Language Explorer.
Some dictionaries do not combine senses with different grammatical categories into a single entry. Instead they separate them into homonyms as in the following example:
| (65) |
|
| (66) |
|
To do this in Language Explorer you would have to create separate entries for each grammatical category.
Some lexicographers prefer to combine all the senses of a lexeme in a single entry, even when the senses belong to different grammatical categories. Notice that the sense numbers begin again at "1" for the verb senses.
| (67) |
|
However Language Explorer does not allow you to do this. Language Explorer numbers each sense consecutively. If you have more than one grammatical category in an entry, you must indicate the grammatical category of each sense as in the following example:
| (68) |
|
A related problem is when a lexeme has more than one sense and all the senses belong to the same grammatical category. Example (63) (repeated here) illustrates the problem.
| (69) |
|
Each sense is a verb and "V" is repeated after each sense number. This is an unnecessary duplication. Language Explorer gives you the option of giving the grammatical category of the lexeme before the first sense. To choose this option go to Tools-Configure Dictionary and click on the Sense line. In the box on the right put a check in the check box next to the line "If all senses share the grammatical information, show it first." This has the effect of changing Example (69) into the following:
| (70) |
|
A translation equivalent is a word in the analysis language that could be used to translate the vernacular lexeme in a particular context. Many bilingual dictionaries start off in their early stages as nothing more than a list of vernacular lexemes with a simple gloss or translation equivalent. A gloss generally tries to capture the essence of the meaning of the vernacular word. On the other hand a vernacular word may have quite a few translation equivalents in different contexts, even for a single sense.
Dictionaries for translators often include translation equivalents for the vernacular lexeme. Other kinds of dictionaries, such as glossaries or a trilingual vocabulary in three column format, also employ translation equivalents rather than full definitions.
Language Explorer has no standard field for translation equivalents. So you have several options:
It is generally not advisable to define a word using translation equivalents. An exception to this rule might be a dictionary designed for bilingual translators whose primary need is to know what options he has for translating a particular word in a particular context. In contrast most language learners need a description of the meaning of a word, especially when the languages are not closely related. There are several reasons for this:
For these reasons a good bilingual dictionary will combine a good descriptive definition with one or more translation equivalents.
There are many ways to approach the development of a dictionary. However I recommend that you use the following step by step procedure. The procedure divides the total task into five basic stages:
This procedure reflects a great deal of thought on the best way to develop a dictionary. It will enable you to work efficiently and systematically to develop your dictionary. It makes maximal use of the power of Language Explorer. Since the production of a dictionary may take many years, this procedure places stages 1 and 2 at the beginning. This enables you to quickly collect a large number of lexemes and quickly expand the list of lexemes into a very basic dictionary that can be used as a tool throughout the length of the project. However Language Explorer does not require you to follow this procedure. You are free to use whatever approach you feel is best.
Lexicographers have proposed many methods for collecting words: (1) use semantic domains, (2) generate a word list from a text corpus, (3) use standard wordlists or published dictionaries, (4) generate a list of all possible wordforms. I recommend using the first two methods. Each has its advantages and the combination will ensure that your dictionary is large, covers all areas of the lexicon, and includes all high frequency words. The third and fourth methods are less useful than the first two because they do not have some of the beneficial side effects of the first two methods. But lexicographers have used them successfully.
This method involves asking speakers of the language to think of all the words that belong to a particular semantic domain. In order to use the method, you need a list of semantic domains. A large list of domains for this purpose has been incorporated into Language Explorer and can be found in the Collect Words tool in the Lexicon area. The list is also available in printable format from the Rapid Word Collection website (http://rapidwords.net/). The website includes detailed instructions for its use in a workshop setting.
Briefly the method involves gathering a group of native speakers of a language in a workshop. The speakers are trained in the method and then work approximately ten days to collect as many words as they can. They are provided with a copy of the list of domains. Each domain includes a few elicitation questions and sample words that help them understand the domain and the type of words that might be included in it. They then use their mental network to think of words in their language that belong to the domain. They write the words down on paper and a typist types them into the program. Approximately 200 language development projects have used the method to collect thousands of words. Most collect well over 10,000 words and one project collected over 20,000. By collecting words in semantic domains, the words are automatically classified. So the result is a classified word list (or what is more popularly called a thesaurus).
This method is by far the most effective method known. It is easy. It is low-tech. It allows native speakers to be involved. It is highly productive. It collects idiomatic phrases as well as individual words. It collects words in their citation form. It doesn't depend on the availability of a large text corpus. And perhaps most important, it classifies the words, giving you an indication of their meaning and providing a basis for later semantic research.
This method involves using a concordance program to generate a list of words occurring in a text corpus. In order to use the method, you need a large text corpus. Otherwise the method will not generate very many words. There are other problems with the method. It does not generate any phrases. Since about one fourth of the lexemes in a language are phrases, this is a very serious drawback.
If you are in an isolating language (one with few affixes), most of the words in the list will correspond with the citation forms in a dictionary. But if you are in an inflecting language (one with many inflectional affixes), most of the words in the list will have affixes. You will need some way to give the correct citation form for each word. This is a time consuming process. Either you need to develop a parser, or someone needs to type the correct citation form for each inflected word.
A word list from a large text corpus in an inflecting language can easily have hundreds of thousands of unique forms. If you find yourself in this situation, it is impractical to type the correct citation form for each inflected word. Instead you will need to work out an automated way of generating the correct citation form.
Language Explorer automatically generates a list of word forms when you import or type a text into the program. The list can be viewed in the Texts & Words area. The program also has powerful editing tools in the Lexicon--Bulk Edit areas that can be used to strip affixes off each form in the dictionary. Unfortunately these tools are not currently available to do bulk edits of the word form list. Hopefully future versions will enable you to efficiently parse the word form list and create any missing dictionary entries.[8]
In spite of these limitations, the text corpus method has many advantages. It collects all high frequency words. It can give an indication of a word's frequency. It gives an indication of the affixation potential of words. And perhaps most important, it provides a text corpus for later semantic research.
Because the semantic domain method and text corpus method each has advantages, I recommend that you use both. Using one or the other will give you good results, but using both will result in significantly more words and provide a better foundation than either method can alone.
For cross-linguistic comparisons, it is good to ensure that words in standard wordlists (such as the Swadesh 200 list or the SIL Comparative African Word List) have been included in the dictionary. It is fairly easy to fill out one of these words lists, type the results, and import them into Language Explorer.
A similar method is to use a published dictionary of another language as a word list. The basic procedure is to look at each word in the dictionary and try to think of the equivalent word (or words) in your language. It is best to get a dictionary that is closely related to your own, because it is more likely that their words will be related to yours and their concepts will be similar to yours. You should also try to find an etymological dictionary of your language family, especially one that includes reconstructed proto forms, because this will also give you etymological information for the words you collect. If you are planning to produce a bilingual dictionary, it would be good to get a dictionary of the analysis language and try to find as many equivalents as possible. If you type both the vernacular and analysis language words, this will help you to produce a reversal index.
Several linguists have used a computer to generate a list of possible wordforms. To do this you would need a knowledge of the phonology of your language. The basic idea is to determine what syllable patterns are allowed in your language and what consonants and vowels can occur in each position in the syllable structure. On the basis of this information the computer generates a list of all possible words. A speaker of the language then goes through this list and marks the ones that are actual words. Bill Poser has developed a program called WordGenerator that can be downloaded from the following website (http://billposer.org/Software/WordGenerator.html).
I recommend that you develop your dictionary by working on one field at a time. I recommend that you add fields in the order presented here. There is a logic to the order, since some steps build on others. You may want or need to skip a step, but each step has proven to be useful in a project.
Language Explorer has all the standard fields available for each entry. There is no need to add blank fields. You can choose which fields will be shown in each view, but the fields are always available. You may need to add a custom (user-defined) field if you have special needs or if you want an extra field for analysis purposes. For more on adding custom fields see section 4.2.14.
The process of doing semantic analysis and writing definitions is the most time consuming task in lexicography. Rather than wait months or years to add a definition, I recommend that you give a gloss or simple definition for each sense of each entry right at the beginning of the project. This is a temporary step so that you will at least have a basic idea of what the word means while you wait for the word to be carefully defined. This is especially important when a word has more than one sense or more than one grammatical category. Without some indication of the meaning, you may make mistakes when filling in other fields. For instance in the Maguindanaon language of the Philippines the word atep can mean 'roof' or 'make a roof'. Giving a short definition for each helps you to realize that the word has two senses and enables you to give the correct grammatical category for each.
The initial definition does not have to be accurate or complete. The purpose is not to provide a polished definition, but just to give some indication of the meaning. The definition may consist of a single word or brief description of the meaning of the word. This should be done quickly at this stage of the project. If you are using the Collect Words tool to add words, it is best to enter a short definition at the same time. If you have lots of words in the database with no definitions, you can add definitions in one of the browse views.
If you are developing a bilingual dictionary, the definition should be in the analysis language. It is easiest to simply give the closest equivalent in the analysis language. If there is no single word that means roughly the same thing, you should give a short phrase describing the meaning. The definition should be put in the Definition field rather than the Gloss field, even if it consists of a single word. We will add a gloss in the Gloss field in a later step.
The Morph Type field is used to distinguish various types of affixes, roots, stems, and phrases. The Morph Type field is used by the parser and interlinear tool to correctly parse words. If you do not specify the morpheme type, the program assumes it is a stem by default. You can view the list of Morph Types in the Lists area. However you cannot add to the list. If you feel you need an additional morpheme type that is not in the list, you can write to the FieldWorks team and suggest that it be added.
The program recognizes two subsets of the list--affixes and non-affixes (roots, stems, and phrases). When you add a new entry to the dictionary, you should use a hyphen to indicate if it is an affix. For instance the English suffix 'ed' should be entered with a preceding hyphen '-ed' and the English prefix 'un' should be entered as 'un-'. When Language Explorer sees the hyphen, it knows that the entry is an affix. So when you indicate the morpheme type in the Morph Type field, the program only displays the list of affixes. Similarly, if there is no hyphen in the lexeme form, the program only displays the list of non-affix morpheme types.
You can specify the morpheme type in the Lexicon--Lexicon Edit--Entry pane by clicking the Morph Type field and then choosing the correct morpheme type from the list. However it is much more efficient to use Bulk Edit Entries—List Choice. You can use the Find function in the Headword field to filter the database for affixes by finding a hyphen, either at the start or end of the field. Specify Morph Type in the Target Field box, then specify the morpheme type in the Change to: box. You can also filter for phrases by finding a space. You can also simply use the check boxes on the left of the pane to choose all the entries that are of a particular morpheme type. In this way you can rapidly specify the morpheme type for all the entries in a large database.
You use the Complex Form Type field to specify various types of complex forms--lexemes that are composed of more than one morpheme. Language Explorer uses this information to format a root-based dictionary. The list of complex forms is maintained in the Lists--Complex Form Types area. There are three basic types of complex forms--derivatives, compounds, and phrases. In a root-based dictionary complex forms are usually presented as subentries. In a lexeme-based dictionary complex forms are usually presented a main entries. However you may choose to produce something in between a root-based and lexeme-based dictionary by making derivatives and compounds main entries, but make phrases subentries. You can configure your dictionary in any of these ways by using the Configure Dictionary tool under the Tools menu. Complex forms may also need to be presented as minor entries to help the user find the correct main entry.
Language Explorer requires you to enter all complex forms as separate entries in the database, but this does not mean that you must present them as main entries in a published dictionary. Instead the program gives you options for how to present them. In order to format each type of entry, the program must know which entries are complex forms and what type they are. Once you have specified the complex form type, you can specify how they should be presented in your published dictionary. You can choose different presentation options in the Lists--Complex Form Types area.
You can specify the complex form type in the Lexicon--Lexicon Edit--Entry pane by clicking the Complex Form Type field and then choosing the correct complex form type from the list. However it is much more efficient to use Bulk Edit Entries—List Choice. You can use the Find function in the Headword field to filter the database for a space in order to find lexical phrases such as idioms. Specify Complex Form Type in the Target Field box, then specify the complex form type in the Change to: box. You can also filter for particular derivational affixes in order to specify derivatives. You can also simply use the check boxes on the left of the pane to choose all the entries that are of a particular complex form type. In this way you can rapidly specify the complex form type for all the entries in a large database.
Grammatical category has traditionally been called 'part of speech'. However the term 'grammatical category' is a more accurate description of what is being recorded. In Language Explorer grammatical category is one part of a larger system called Grammatical Info. Grammatical Info includes Grammatical Category, Inflection Class, Inflection Feature, and Exception Feature. Since different senses of a word may have different grammatical categories, these fields are sense level fields.
In Language Explorer grammatical category is subordinate to sense. In other programs, such as Shoebox, you could have a single grammatical category with several senses under it. But in FieldWorks you must specify the grammatical category of each sense. If you add a second sense to an entry, the grammatical category will be copied from the first sense to the second. If this is not correct, you will have to correct it. If you are not sure of the grammatical category, you can select <Not Sure> from the list. You can specify the grammatical category in the Lexicon Edit--Entry pane by clicking the Grammatical Category field and then choosing the correct grammatical category from the list. However it is much more efficient to use Bulk Edit Entries—List Choice. If your language has inflectional or derivational affixes that indicate the grammatical category of the word, you can use these affixes to quickly identify and specify the grammatical category. For instance in English the derivational suffixes '-ment' and '-tion' produce nouns, the suffixes '-ize' and '-ate' produce verbs, the suffixes '-ful' and '-able' produce adjectives, and the suffix '-ly' produces adverbs. If your language has affixes like these, you can use them to specify the grammatical category for large groups of words all at once. To use this technique, use the following procedure:
You can Filter for the affix, specify Category in the Target Field box, then specify the category .
If your language does not have affixes that indicate the grammatical category, or if some words have no affixes, you can simply use the check boxes on the left of the pane to choose all the entries that are of a particular category. Use the following method:
Using these methods you can rapidly specify the category for all the entries in a large database.
Many languages have inflectional affixes that occur on nouns, verbs, and other grammatical categories. Some languages have a few nouns or verbs that are irregular in their inflection. Other languages have large classes of nouns or verbs that take different sets of affixes. Linguists like to organize the inflected forms of a word in a chart called a 'paradigm'. The term paradigm is also used to refer to all the inflected forms of a single word. Each inflected form is called a 'paradigm form'.
Some lexicographers want to indicate one or more of these inflected forms in the published dictionary. For instance most English dictionaries indicate the plural form of irregular nouns (woman, women) and the forms of irregular verbs (do, does, doing, did, done). (If your language only has a few irregularly inflected forms, they would normally be handled by creating a separate entry for each irregularly inflected form.) Other languages have noun classes or verb classes that need to be indicated in the dictionary. For instance the plural forms of many nouns in most Bantu languages cannot be predicted from the singular. So the tradition in Bantu language dictionaries is to indicate the plural form of each noun, as in the following entries from Lunyole:
| (71) |
|
| (72) |
|
You may also want to generate one or more sets of inflected forms for each word to help you analyze the patterns, determine what classes you have, and identify morphophonemic rules. For instance you might want to create a custom field in which you list the plural form of each noun or the past tense of each verb. In order to create a field for a particular paradigm form, do the following steps:
An inflection class is a set of nouns, verbs, or other grammatical category that takes an unconditioned allomorph of an affix. For instance the English nouns that form their plurals by replacing a vowel (man/men, woman/women, goose/geese) form an inflection class. Inflection class is explained more fully in Andy Black's 'A Conceptual Introduction to Morphological Parsing', which can be found in the Language Explorer Help menu.
The parser needs to know the inflection class of a word in order to know what affixes it can take. The parser also needs to know the inflection class of the affixes that can occur on stems belonging to the class. The inflection class of both stem and affix must match before the word will parse correctly.
Some lexicographers also want to indicate the inflection class in a published dictionary. To do this use Tools-Configure-Dictionary. Under Main Entry-Senses-Grammatical Info check the line Inflection Class.
You can specify the inflection class of words in the Lexicon--Lexicon Edit--Entry pane by clicking the Inflection Class field in the Grammatical Functions section and then choosing the correct inflection class from the list. However it is much more efficient to use Bulk Edit Entries—List Choice. You can use the Find function in the Category field to filter the database for a particular grammatical category. Specify Inflection Class in the Target Field box, then specify the inflection class in the Change to: box. If you have set up a Paradigm field for the grammatical category, you can also filter for the particular allomorph that indicates the inflection class. You can also simply use the check boxes on the left of the pane to choose all the entries that are of a particular inflection class. In this way you can rapidly specify the inflection class for all the entries in a large database.
Inflection features are characteristics of morphemes, such as gender and number in Indo-European languages, or "noun class" in Bantu languages. Inflection features are explained more fully in Andy Black's 'A Conceptual Introduction to Morphological Parsing', which can be found in the Language Explorer Help menu.
The parser needs to know the inflection features of a word in order to know what affixes it can take. The parser also needs to know the inflection features of the affixes that can occur on stems belonging to the class. The inflection features of both stem and affix must match before the word will parse correctly.
Some lexicographers also want to indicate the inflection features of words in a published dictionary. To do this use Tools-Configure-Dictionary. Under Main Entry-Senses-Grammatical Info check the line Inflection Features.
You can specify the inflection features of words in the Lexicon--Lexicon Edit--Entry pane by clicking the Inflection Feature field in the Grammatical Functions section and then choosing the correct inflection feature from the list. However it is much more efficient to use Bulk Edit Entries—List Choice. You can use the Find function in the Category field to filter the database for a particular grammatical category. Specify Inflection Feature in the Target Field box, then specify the inflection feature in the Change to: box. If you have set up a Paradigm field for the grammatical category, you can also filter for the particular morpheme that indicates the inflection feature. You can also simply use the check boxes on the left of the pane to choose all the entries that are of a particular inflection feature. In this way you can rapidly specify the inflection feature for all the entries in a large database.
In some languages the lexeme form and the citation form are identical. If this is the case in your language, you can ignore this step.
Words are first added to the database in the Lexeme Form field. If your language uses an inflected form for the citation form, the words may have been collected and entered in their citation form. So in the initial stages the Lexeme Form field may actually contain the citation form. The Lexeme Form field is intended to contain the unaffixed stem and the Citation Form field is intended to contain an inflected form that will be used as the headword in the dictionary entries. So if your language uses an inflected form for the citation form, you need to fix this situation by copying the contents of the Lexeme Form field into the Citation Form, and then deleting inflectional affixes from the word in the Lexeme Form field so that it is only the stem. To accomplish this, do the following steps:
Most dictionaries will benefit from an indication of how each word is pronounced. This is especially important for languages in which the orthography is not fully phonemic. It is also important for dictionaries designed to aid in language learning. Even if you do not include a pronunciation field for every word, it is important to indicate variant pronunciations that are not indicated in a standardized orthography. For instance the English word 'either' can be pronounced ['iðɚ] or ['ajðɚ]. In Lexicon Edit you insert a pronunciation by clicking the Pronunciation field. You can insert more than one pronunciation if the word has multiple pronunciation variants. If you wish to use IPA, you should set up an IPA writing system for the vernacular language. To do this, go to the Format menu and click Setup Writing Systems. You can then specify what writing system you want to use in the Pronunciation field by right clicking the Pronunciation field and then clicking Writing System. To fill in the Pronunciation field using the Bulk Edit tools, use the following procedure:
You can use your dictionary to help analyze the phonology of the language. One important tool in this process is the CV Pattern field. For instance the English words 'stitch' and 'shred' both have the phonological pattern 'CCVC'. But notice that the phonological pattern does not match the pattern of letters in the orthography. In order to find all the words in English with the CV pattern 'CCVC', it is necessary to generate a CV Pattern field for each word in the language. The CV Pattern field should match the phonological pattern of the words, not the orthographic pattern. A CV Pattern field is useful in studying syllable structure, allophonic variation, tone patterns, and other issues in phonology. In Lexicon Edit the CV Pattern field is normally hidden until you enter a pronunciation in the Pronunciation field. To fill in the CV Pattern field using the Bulk Edit tools, use the following procedure:
If your language has lexical tone or stress, you should first indicate it in the Lexeme Form, Citation Form, or Pronunciation field as appropriate. In order to analyze the tone or stress patterns, you will need to fill in the Tone field. For instance the English word that is spelled 'record' is actually two lexemes with two different stress patterns /'record/ and /re'cord/. The stress pattern for /'record/ is SU and the pattern for /re'cord/ is US (where S = stressed and U = unstressed). If your language has both primary and secondary stress, you can use P = primary, S = secondary, U = unstressed. In a tone language you can use abbreviations such as H = high, M = mid, L = low, R = rising, and F = falling. You can use the Tone field to indicate tone patterns or stress patterns, whichever your language has. In Lexicon Edit the Tone field is normally hidden until you enter a pronunciation in the Pronunciation field. To fill in the Tone field using the Bulk Edit tools, use the following procedure:
Once you have produced a simple definition (see section 4.2.1), you can efficiently add a single word gloss for each word. If you cannot think of a one-word equivalent, then give a very short phrase, the shorter the better. The gloss is used in interlinearizing texts, so it needs to be as short as possible to keep the lines from becoming too long. In interlinear texts it is conventional to put a period or underline between multiple words in a gloss (e.g. older.brother or older_brother). The gloss can also be used in a browse view to give a short indication of a word's meaning. To fill in the Gloss field using the Bulk Edit tools, use the following procedure:
Once you have filled in the Gloss field, you can efficiently add a reversal index entry for each sense.
Language Explorer has a standard set of fields. However you may need extra fields that are not included in the standard set. For instance you may want to record particular forms of the noun or verb paradigms, such as irregularly inflected noun plurals, or a particular inflected verb form that reveals various verb classes. You may also want to copy some field and manipulate the contents in some way to aid in your analysis of the language. Two such fields are included in the standard set--the CV Pattern field and the Tone Pattern field. Both these fields have proven to be very useful in phonological and tone analysis.
To add a custom field click Tools--Custom Fields. Specify if the new field is an entry level or sense level field. Give the field a name, give a description of the field, and specify what writing system(s) should be used in the field.
Semantic investigation is best done in context--in the context of semantic domains and in the context of corpus studies. It is necessary to apply intuition in both contexts. Intuition is needed to identify the members of a semantic domain and to interpret the data derived from the corpus method. Identifying lexical sets within a domain enables us to look at paradigmatic lexical relations, and to contrast and compare the members of the lexical set. Identifying collocates in a text corpus enables us to look at syntagmatic relations. The combination of the two is quite powerful. The Collect Words tool includes a list of semantic domains to help you collect and classify your words. The Texts & Words area enables you to develop a text corpus and generate a concordance of textual examples to help you study how a word is actually used.
Consider the following three sentences that use the word ‘follow’:
| (73) |
|
We recognize that the three sentences represent three different senses.
In each of the sentences follow is a transitive verb with a person as subject and various things as objects. This tells us very little about the meaning of the word. Instead we have to use our intuition about what we know of the word. It helps to have some semantic theory to shed light on the problem. But the primary method that all lexicographers use is to use our native speaker intuition about what a word means and how it is used.
We can use our text corpus to generate a concordance of all the sentences that use the word. But this will not give us some very important information that we need to accurately define the word.
The first question we need to ask ourselves is, “What semantic domain does this word belong to?” The first example sentence is in the domain of movement, specifically in the realm of one person following another person wherever they go. In the Dictionary Development Process (DDP) list of domains this is 7.2.5.2 'Follow'. The second sentence is in the domain of travel, specifically in the realm of giving directions. This is DDP domain 7.2.4 'Travel' or 7.2.4.6 'Way, route'. The third sentence is in the domain of argumentation, specifically in the realm of listening and understanding someone giving a reasoned argument. This is DDP domain 3.2.4 'Understand'.
The second question we need to ask ourselves is, “What other ways do we have of saying the same thing?” We could reword the first sentence as:
| (74) |
|
We could reword the second sentence as:
We could reword the third sentence as:
| (76) |
|
As we do this we are forming lexical sets for each word:
| (77) |
|
There is no way to form these lexical sets using the text corpus method. We must use our intuition within each relevant semantic domain. So the basic procedure is to identify the semantic domain of each sense. Then within the domain you need to list all the members of the lexical set that the word belongs to. You should work systematically through all the semantic domains of the language.
A domain template is a list of questions to ask about each member of a lexical set. It is best to maintain the words, questions, and the answers to the questions in a chart format. List the questions along the horizontal axis and the words along the vertical axis. Pick the most important or frequent member of the lexical set and investigate it thoroughly. Then pick another member of the set and investigate it. As you investigate each member of the set, you will discover more and more issues to investigate and questions to ask. Patterns will emerge. You can develop a standardized definition for the members of the set. Domain templates will help you be more systematic, will yield better insights, and will speed up the process of investigating and defining the words. Language Explorer does not currently include a place to record domain templates.
The basic procedure is to generate a concordance of all the sentences in the text corpus that use the word. Then look in the context for clues to the word's meaning. For instance if the word is a verb, you would look at what words occur as the subject, object, and indirect object. If the word is a noun, look at what words modify the noun and what verbs it occurs with. Look in the context for any word or set of words that occur frequently. In Language Explorer you can use the Concordance feature in the Texts & Words area to generate a concordance of a word.
Once you have written good definitions of all the words, you need to work systematically through all the entries to make sure they are ready for publication. You should work through the dictionary in alphabetically order to make sure you don't miss any entries. Develop a checklist of things to look for. The checklist should cover the following items:
If the entry contains more than one sense, make sure the senses are related. If they are unrelated, split the entry into homonyms. Language Explorer automatically assigns homonym numbers. If you need to change the order of the homonyms, add the homonym number column to a browse view and edit the numbers there. For more on homonyms see section 3.2.5.
It is sometimes difficult to tell if two senses of a word are related or unrelated. Consider the following entry:
| (78) |
|
Some of the senses are obviously related. But it is difficult to decide whether others are related. There are several tests. If the two are derived historically from different sources, they are homonyms. If you ask several native speakers to explain the relationship between the senses and each gives a different explanation, they are probably homonyms. If the speakers can't provide a reasonable explanation, they are probably homonyms. The two senses may be related far back in time, but they may have changed so much over the centuries that it is difficult now to see the connection. If a linguist cannot see a reasonable connection and native speakers cannot give one, you should treat them as homonyms. It helps if you have a good understanding of how words change in meaning over time. Such an understanding comes from extensive study of historical linguistics and from study of patterns of polysemy.
In example (78) senses 1-3 are related by the idea of a sound produced by tapping. Senses 5 and 6 are related by the idea of drawing a liquid from a pipe. Most native speakers would link sense 4 to 1-3 with an explanation such as, "A tap on a shoe makes a tapping sound on the ground, like in tap dancing." So we would join sense 4 to 1-3. But it is difficult to see any connection between senses 1-4 and 5-6. So we would split this entry into two:
| (79) |
|
| (80) |
|
Look at each sense to make sure each one truly represents a separate sense. Combine or split senses as needed. The first draft of the Lunyole dictionary contained the following entry:
| (81) |
|
Each sense would be expressed by a different word in English. But it was clear that the Lunyole word actually had only one general meaning. So all the senses were combined into a single sense:
| (82) |
|
Put the most basic sense first. Group related senses. I recommend that you group senses on the basis of semantics rather than on the basis of grammatical category. However most dictionaries group senses on the basis of grammatical category. In example (79) above (repeated here) I ordered the senses on the basis of semantics. Sense 1 is most basic and sense two is very close to it. Sense 3 is closer to 1 and 2 than sense 4 is. So I would order them accordingly:
| (83) |
|
However some lexicographers prefer to put all the verb senses together and all the noun senses together:
| (84) |
|
Some lexicographers automatically put nouns before verbs (or verbs before nouns):
| (85) |
|
You can also demote and promote senses in order to create a hierarchy of senses:
| (86) |
|
Language Explorer allows you to order senses as you wish. In Lexicon Edit in the Entry pane you can click next to the sense number and get a menu with options, including moving a sense up or down and promoting or demoting a sense.
Make sure that the example sentences match the definitions. Make sure that the definitions match the grammatical category. Check for missing information.
Make sure each definition follows the principles and style that you have established. Make sure each definition in an entry fits with the others. You can allow the definitions in secondary senses to inherit information from the primary sense. In the entry below, the word 'race' has been carefully defined in the first sense. But the second and third definitions are much shorter because they depend on the information in the first definition.
| (87) |
|
Language Explorer has a spell checking function that can help you find spelling errors. You can install spelling dictionaries for each of your analysis languages and then use the spell checking function to find misspelled words. You can also develop a spelling dictionary for the vernacular. For instructions on how to do this see the Help files.
There are several things you can do to find errors in your data. One thing I do is to use one of the browse views to systematically sort the database on each field. I go to the top of the file and then to the bottom of the file because some characters such as an extra space or punctuation mark sort before or after the alphabetic characters. I also sort each field from right to left and then go again to the top and bottom of the database. Sometimes it is helpful to scan through the entire field looking for unusual things.
The last thing you should do is print the dictionary and proofread the printout. This will help you not only find errors in the data, but will also bring out any problems in the printing process, such as the handling of fonts.
Language Explorer currently has a number of export and print options. For instance you can print the Dictionary views for proof reading the content. However it does not have a publication formatting function, meaning you cannot print a photo-ready copy directly from Language Explorer. In order to print the dictionary for publication you must first export the database and then format it using another software package. You can export the configured dictionary to XML or SFM. (You configure the dictionary using the Configure Dictionary tool.) You can export the lexical database in MDF format and then print it using a program such as Lexique Pro. Lexique Pro enables you to publish in print or on the web. You can export the reversal index to XML or SFM.
Once you have produced the dictionary entries, the last stage is to prepare the material that comes at the beginning and end of the book. Language Explorer currently does not provide a place for you to enter this material in the program. You would need to use another program, such as a word processor to produce the materials. The front and back matter includes the following parts.
Pick a design that reflects something of the culture, such as a cultural artifact. Use a color scheme that is used by the people and that they find attractive. This will help the people to feel that it is their dictionary. Make it eye-catching so that it will sell well.
The layout of the title page varies depending on the publishing traditions in the country where the book will be published. You should find examples of dictionaries and use them as a pattern.
The layout and contents of the copyright page depend on the laws of the country where the book will be published. You should consult with the publisher on the requirements.
You can use other published dictionaries as a pattern. The table of contents should be one of the last things you print. In order to get all the page numbers correct, you should draft the table of contents (so you know how long it will be), then print the rest of the book. Then you can insert the correct page numbers into the table of contents.
You can use other published dictionaries as a pattern. Give information about the language. Give information about how the dictionary was produced and by whom. Explain the structure and parts of the article. Give credit where credit is due. Remember—few people will read a long introduction. Keep it short, sweet, and to the point.
Include a map that locates the language area within the country. Also include a large scale map with important towns and geographical features. Mark the boundaries of the language area. Indicate dialect areas and mark dialect boundaries.
You should maintain a list of abbreviations throughout the length of the project. If you didn’t keep a list, you will have to search your dictionary for them. Language Explorer maintains several lists of abbreviations in the Grammar area (e.g. Categories) and the Lists area (e.g. Complex Form Types).
You should include an orthography guide if your language is newly literate. Dictionaries have proven to be a powerful influence on standardizing the orthography, promoting literacy, and developing literature. People will refer to it for the 'correct' way to spell a word.
Language Explorer has a tool that will produce a grammar sketch automatically based on the information it gleans from your data in the lexicon and elsewhere in the project. You can generate the grammar sketch in the Grammar--Grammar Sketch area by clicking Generate. You can also regenerate it periodically to keep it up to date with the changes you have made to the data. When you regenerate it, Language Explorer overwrites the old file. You can save the grammar sketch in order to edit it outside of Language Explorer prior to publishing. But if you edit it outside of Language Explorer, you cannot update your edited file by having Language Explorer regenerate it. Instead of simply updating the information, Language Explorer deletes the old file and regenerates it. So you would lose all the changes you had typed in.
Some dictionaries include tables for important lexical sets. Alternatively you could include an index of semantic domains. If you only want to include a few lexical sets, consider including tables for the numbers, days of the week, months of the year. If you want to include proper nouns—personal names, family names, place names—it saves space to list them in a table rather than including them in the dictionary proper. These materials can also be put after the dictionary proper as appendixes.
This is where you would put the alphabetized dictionary. You will need to print it and make sure the pagination and headers are correct. Language Explorer currently does not have a fully developed print function. In order to correctly format the dictionary, you might need to export it and print it using another program such as Lexique Pro. (See Export in the Help files for more on exporting and printing the database.)
An appendix is the same as a table, except that tables are at the beginning of the book and appendixes are at the end. A good rule to follow is to keep tables short. Anything long should be made into an appendix at the end.
The bibliography can go at the end of the introduction or at the end of the book, depending on its size. If very little has been published about the language or in the language, list everything. List any previous dictionaries, especially if you referenced them or incorporated them. List any grammars of the language. List any literacy materials, such as a published orthography guide. List language learning materials. List published texts that you used in your text corpus or in example sentences.
There are several publishing companies that specialize in minority language dictionaries. Look at published dictionaries in your region to see who the publisher was. Often the national university will be interested in publishing a dictionary.
Determine how many copies to print. Your publisher should be able to help you decide how many copies to print. Dictionaries tend to sell well. But minority language groups are often too poor to afford a large, well-bound book. On the other hand you may sell lots of copies to university libraries around the world. If your language is large and important for commercial or political reasons, you may sell lots of copies to people needing to communicate in the language. It is better to sell out and have to reprint, than to print too many and go bankrupt.
Find a source of funding. Your most likely sources of funding are the national government, international aid organizations, educational institutions, and private foundations. The cheapest way to publish a dictionary is to post it on the Internet. There are a number of websites willing to post minority language dictionaries as part of their collection.
Language Explorer has a lot of great tools, features, and helps that we don't want you to miss. If you are like me, you like to go exploring on your own. That's fine. Go exploring and have fun. But if you are like me, you also sometimes wish someone would explain some really odd menu item and what it is used for. So if you can't figure something out on your own, come on back and I'll try to explain it.
Before we look at specific areas of Language Explorer, let's look at some general features.
In Language Explorer the screen is divided into three basic parts. Along the left of the screen is a list of areas. Across the top are menu bars. The rest of the screen is the work area where you type and do other tasks.
There are four major areas of Language Explorer that are listed in the bottom left of the screen--Lexicon, Texts & Words, Grammar, and Lists. If you click on one of the four areas, you will see in the top left of the screen a list of the views and tools that are available in each of the areas. If you click on one of these views, Language Explorer presents a different work area where you can work on various aspects of your project. I would recommend that you open up each of these work areas to see what is available in Language Explorer. I will explain the purpose of each below.
The menu bars across the top of the screen are typical of many software applications. The top line is a series of menus. When you move from area to area in Language Explorer, the list of menus does not change, but the items under each menu change. This is because the menu items are often specific to the area that you are working in. The second menu bar consists of icons and dropdown menus. These also change when you switch to a different area.
There are also other menus that are specific to a particular pane or field in one of the work areas. These can be accessed
by clicking on the menu icons that look like this  or this
or this  . Some of these menu icons only appear when you click on the field. You can also open the menus by right clicking on the line
or the field name.
. Some of these menu icons only appear when you click on the field. You can also open the menus by right clicking on the line
or the field name.
Occasionally you will use one of the menus to change a setting in Language Explorer, but nothing happens. This is actually
a problem with the program. The first thing you should try is to click the Refresh the screen icon  on the menu bar at the top. Often this will cause Language Explorer to implement the change.
on the menu bar at the top. Often this will cause Language Explorer to implement the change.
It is important to be able to view your data in many different ways. For instance you may want to see what an entry will actually look like in print. So the Lexicon Edit view includes a Dictionary Preview pane. You can see how the entire dictionary will look in the Dictionary view. The Reversal Indexes view enables you to see how a reversal index will look. The Classified Dictionary view enables you to see how the dictionary will print as a semantically classified dictionary or thesaurus. It is important to note that these are not actually print previews. You can print these views, but they will not be photo ready copy for a proper publication. Language Explorer does not yet have proper typesetting functions. These views do, however, give a preview of what the data can look like after proper typesetting. They also show how entries are structured for export to other software. For more on exporting your data see section 4.4.6.
You may also want to view a number of entries at one time with each field in a separate column in a table format. This kind of view is called a browse view. A browse view is included in the Lexicon Edit tool. The Browse pane consists of a browse view in which you can directly edit many fields. In addition the Bulk Edit tools use a browse view. These browse views are especially useful when you are working on a particular field. The browse views allow you to pick the columns you want to see, and arrange, size, sort, and filter them. (For more on the Browse pane see the Help topic 'Lexicon Browse overview'.)
Typically in a browse view each row displays a different entry and each column displays a different field. This works fine as long as each field only occurs once in an entry. For instance most of the entry level fields only occur once per entry. But many other fields can occur more than once in an entry. For this reason the Bulk Edit Entries tool will change the way your data is presented depending on which field you want to edit. For instance if you want to edit the Citation Form field, it will place each citation form on a separate line. This has the effect of displaying each entry on a single line. But if you want to edit the Example field, it will place each example sentence on a separate line. Since there may be several example sentences in an entry, this means that the entry level fields will be duplicated for each example sentence. In this way you can see and edit each occurrence of the field you are editing, but also see the other fields in the entry. (For more on data views see section 2.2.3. For more on the Bulk Edit tools see the Help topic 'Bulk Edit Entries overview'.)
Most dictionaries are organized by sorting the headword. However you may sometimes want to view the data by sorting on a different field. Language Explorer enables you to sort on any field in a browse view. You can sort top to bottom, or bottom to top. You can sort left to right, or right to left. You can set up special sort orders for each language in the database. You can change the sort order in Dictionary View by changing the vernacular language sort order. (For more on sorting see the Help file topic 'Sort data'.)
Sometimes you want to concentrate on just one type of data, for instance on nouns. The browse views enable you to filter on any field. The Filter dialog box has a number of simple options that are easy to use and will enable you to filter for many kinds of data. However Language Explorer also enables you to use regular expressions (a powerful computer language) for very complicated filters. It may take some effort to learn how to use regular expressions, but they will enable you to filter your data in many more ways. (For more on filtering see the Help file topic 'Filtering data overview'.)
There are six types of fields in Language Explorer:
 that turns a feature on or off.
that turns a feature on or off.
The Lexicon area is where you create, edit, and manage your dictionary database, which is called the Lexicon in Language Explorer. You also use the Lexicon area to generate various publications based on your database.
The Lexicon Edit area is where you create and edit particular lexemes. The area is divided into three panes. On the left is the Entries pane, which is a browse view. You can edit some of the fields in the Entries pane, but not others. If you click on one of the rows, the blue fields cannot be edited, but the white fields can. You can
only edit the simple text fields. (However you can edit almost every field using the Bulk Edit Entries area, which is also a browse view.) The primary purpose of the Entries pane is to help you to sort and filter your database to find those entries that you want to work on. You can show any field
in the Entries pane by clicking on the Configure which columns to display icon  in the top right corner of the pane. If a field is being displayed, you can sort the database on it by clicking on the header
line at the top of the column. The column that is currently being sorted on will have a blue arrow next to it
in the top right corner of the pane. If a field is being displayed, you can sort the database on it by clicking on the header
line at the top of the column. The column that is currently being sorted on will have a blue arrow next to it  . (For more on sorting see the Help file topic 'Sort data'.) You can also filter the database by filtering the data in a particular field. You access the filter
menu by clicking on the dropdown menu icon
. (For more on sorting see the Help file topic 'Sort data'.) You can also filter the database by filtering the data in a particular field. You access the filter
menu by clicking on the dropdown menu icon  in the second line at the top of the column. Different columns permit different kinds of filters. So this menu may change
depending on the type of field. (For more on filtering see the Help file topic 'Filter data'.)
in the second line at the top of the column. Different columns permit different kinds of filters. So this menu may change
depending on the type of field. (For more on filtering see the Help file topic 'Filter data'.)
On the right is the Entry pane. At the top is a pane that gives you a preview of how the entry might look in print. You can configure how your dictionary will look by using the Configure Dictionary tool that is accessed under Tools on the menu bar.
The bottom part of the Entry pane displays a single entry with each field on a separate line. You can edit each field in this pane.
If you are not using a field, you can choose to hide it by clicking on the field, clicking on the icon, clicking Field Visibility, and then selecting one of the options. When you click on the Show Hidden Fields icon at the top of the Entry pane, Language Explorer will hide the fields that you are not using. When the check box is unchecked and looks like this
 , some of the fields are hidden. When the check box is checked and looks like this
, some of the fields are hidden. When the check box is checked and looks like this  , all of the fields are visible, even the ones you are not using. For a description of each of the fields in the Entry pane see section 6.2.
, all of the fields are visible, even the ones you are not using. For a description of each of the fields in the Entry pane see section 6.2.
The Browse area consists of a single browse view of the lexicon with each entry on a separate line and each field in a separate column. As with the Entries pane in Lexicon Edit, you can only edit the text fields. You can sort on any field. If you sort on a field that occurs more than once in an entry, each instance of that field will be put on a separate line. This results in the entry being split up. You can also filter each field.
The advantage of the Browse area is that you can use the entire screen. This enables you to see many entries and fields simultaneously. The primary disadvantage of the Browse area is that you cannot edit efficiently, which is why we have the Bulk Edit areas.
The Dictionary area presents your lexicon formatted as an alphabetized dictionary. You can change how it is formatted using the Configure Dictionary tool that can be accessed from the Tools menu. The Configure Dictionary tool allows you to choose various formats, choose which fields to include, order your fields, format particular fields using styles, add punctuation before or after a field, etc. In this way you can get your dictionary to look just the way you want it. The Dictionary area also allows you to proofread your dictionary prior to publication.
The Collect Words area allows you to efficiently type words that were collected during a Rapid Word Colletion (RWC) workshop. (Rapid Word Collection is the first step in the larger Dictionary Development Process (DDP), which is the method described in this paper.) You can learn more about the RWC method of collecting words by visiting the RWC website (http://rapidwords.net/). You can download the RWC materials and instructions for how to use them from the website. The Collect Words area consists of the DDP semantic domains. The list of domains is displayed in the column on the left. Each domain consists of a short description and a series of elicitation questions with example words. The description and questions are displayed on the top right. Below this is a place where you can type the vernacular words that belong to the domain together with a short gloss or definition.
As you type words into this area, Language Explorer creates a new entry for each one in your lexicon. The word entry area
is a browse view. So you have the ability to add columns to the display. The default view only shows two columns--the Word (Citation Form) column and the Meaning (Definition) column. The form you type into the Word (Citation Form) column goes into the Citation Form field. What you type in the Meaning (Definition) column goes into the Definition field. You can use the icon in the top right corner to change which columns are displayed in the browse view. For instance if you want to enter the lexeme
form of the word instead of the citation form, you can replace the Word (Citation Form) column with the Word (Lexeme Form) column. Likewise, if you want to enter a gloss instead of a definition, you can replace the Meaning (Definition) column with the Meaning (Gloss) column.
Notice that the four columns--Word (Citation Form), Word (Lexeme Form), Meaning (Definition), and Meaning (Gloss)--are not the same as their respective fields. The Meaning (Definition) column displays the contents of the Definition field. But if you have not entered a definition, it will display the contents of the the Gloss field in parentheses.
Each word you type is also assigned to the current semantic domain. However if the word you type matches an existing lexeme in your lexicon, Language Explorer merely adds a new sense to the entry and assigns the sense to the current semantic domain in the Semantic Domain field. However if both the lexeme and definition match what is in your lexicon, Language Explorer merely adds the current semantic domain to the Semantic Domain field in the respective sense.
Collect Words works well when you are just starting your project. However if you already have a large dictionary, Collect Words will very likely add lots of duplicate senses to your lexicon. This can result in a lot of extra work to merge the duplicate senses. One way around this problem is to first classify all existing senses in your dictionary. Then when you use Collect Words, all the existing words in a domain will already be displayed. Unfortunately there is not an easy way to classify existing senses. The Semantic Domain field in the Lexicon Edit Entry area has a tool in the Choose Semantic Domains dialog box called Suggest. It will suggest possible semantic domains for the word, based on what you have entered in the the Gloss field.[9]
The Classified Dictionary area displays your lexicon as a semantically classified dictionary using the list of semantic domains in the Semantic Domain field. The display consists of each semantic domain and a list of all the lexemes that belong to the domain. Each lexeme is followed by the relevant sense number and the definition from the sense.
If you have not classified any of your lexemes by semantic domains, there will be nothing in this area. So to use this feature, you must first classify your lexemes. The easiest way to do this is to use the Collect Words area to think of all the words that belong to each domain.
The Semantic Domain field is a sense level field. A lexeme may have several senses, but only one of those senses may be relevant to a particular semantic domain. The other senses may belong to other domains. So the Classified Dictionary area displays each sense under its own domain. If a sense is not classified under any domain, it will not be displayed anywhere in the classified dictionary.
The Bulk Edit Entries area contains a number of tools to help you efficiently fill in and edit fields. These tools enable you to work on a particular field in every entry in your lexicon. The top part of the area consists of a browse view with each entry on a line and each field in a separate column. The bottom part of the area consists of six tools. The tools can be found on the six tabs at the bottom. When you click on one of these tabs, the bottom of the area changes to display the options that you need to choose in order to use the tool.
Much of the work involved in developing a lexical database is repetitive. The team that developed Language Explorer carefully thought through the kinds of editing functions that lexicographers need to perform and developed the Bulk Edit tools to make these tasks easy. The sections below explain each of the tools and how to use them. The Bulk Edit tools can help you accomplish many tasks in a fraction of the time that it would take you to do the task in Lexicon Edit. Using these tools can save you months of tedious typing.
The top part of the Bulk Edit Entries area consists of a browse view of the lexicon, but there are a few special features that you need to be aware of. In order
for you to work on a field, that field needs to be displayed in one of the columns. You can choose which fields are displayed
by clicking the Configure which columns to display icon in the top right corner of the pane. This will display a list of fields that are available. If you don't see the field
that you need in the list, click the More Column Choices option at the bottom. This will bring up a dialog box where you can choose which fields you want to display, change their
order, see which ones can be bulk edited, and (if you have set up more than one writing system or analysis language) choose
which writing system should be used in the field. This gives you good control over what fields you see.
You can choose to sort on any field by clicking the field name at the top of the column. The field that is currently being
used to sort the lexicon will have a blue triangle next to it that looks like this . You can do a secondary sort on a second field by holding down the Shift key and clicking the field name. A small blue triangle
will appear next to the second field name. If you right click on a field name, you can choose to sort the field from the end
(right to left) or by the length of the field contents. (For more on sorting see the Help file topic 'Sort data'.)
You can filter the contents of a field by clicking on the dropdown menu icon in the second line at the top of the column. The Show All option turns off the filter. The Blanks option filters for fields that are empty. The Non-Blanks option filters out fields that are empty. The Filter for option enables you to filter for a string of characters. This option also permits you to use regular expressions. Regular
expressions are special codes used by computer programmers that enable you to filter for complex kinds of things such as consonants,
vowels, and single words. Different kinds of fields permit different kinds of filters. For instance a list field has an additional
option Choose that enables you to filter for one or more items in the list. You can also filter out items. A check box field has "yes"
and "no" options. (For more on filtering see the Help file topic 'Filter data'.)
On the left is a column of check boxes. In order for a change to be made to an entry, there must be a check  in that row. The check box icon
in that row. The check box icon  at the top of the column has three options. The Check All option puts a check mark in each row. The Uncheck All option removes all the check marks. If you have some of the boxes checked and then select the Toggle option, all the checked boxes will become unchecked and all the unchecked boxes will become checked.
at the top of the column has three options. The Check All option puts a check mark in each row. The Uncheck All option removes all the check marks. If you have some of the boxes checked and then select the Toggle option, all the checked boxes will become unchecked and all the unchecked boxes will become checked.
Using the Sort feature, the Filter feature, and the check boxes enables you to focus on any subset of the data that you want to work on and make changes to just those fields and entries that you want to change.
The List Choice tool enables you to work on a list field. The contents of a list field are chosen from an authority list. These lists are maintained in the Lists area or the Grammar area. You cannot type in a list field. Instead you choose one of the items in the authority list. That is why this tool is call List Choice--because you choose an item from a list. The List Choice tool is the only one that works on list fields. The other Bulk Edit tools work on text fields.
To use the List Choice tool you must first specify which field you want work on in the Target Field box. The field must be showing in one of the columns. In the Change To box you choose which item in the list you want. Click Preview to see what changes will be made. If you are happy with your choices, click Apply to make the changes permanent. (You can always click Undo to reverse the changes. But if you leave the Bulk Edit area, you can no longer reverse the changes using the Undo icon.)
The List Choice tool is especially useful for filling in (or changing) the Grammatical Category field, the Inflection Class field, and the Inflection Features field. You would also use it to change check box fields like the Exclude As Headword field.
The Bulk Copy tool copies the contents of the source field into the target field. Both fields must be showing. There are three options in the If the Target field is not empty box that give you control over what happens when there is already something in the target field.
The Bulk Copy tool is especially useful for filling in a field that is very similar in content to another field. For instance you could copy the contents of the Lexeme Form field into the Citation Form field and then modify one or the other.
The Click Copy tool was designed to copy a single word from one field into another field. The basic idea is to click on a word in one field and have that word copied into another field. There are several options. The String, reordered at word clicked option enables you to copy more than just one word. There are also two options that give you control over what happens when there is already something in the target field.
The Click Copy tool is especially useful for filling in the Gloss field by clicking on a word in the Definition field. You can also use it to fill in the Reversal Entries field by clicking on a word in the Definition field.
The Process tool was designed to enable those with good computer skills to use advanced tools like CC tables, ICU transducers, TECkit files, and Regular Expressions to modify the contents of a field.
The Process tool is especially useful for transforming writing systems. For instance you could use it to update your orthography. You could also use it to transform the contents of the Citation Form field into an IPA phonetic transcription in the Pronunciation field. The power of the advanced tools make it possible to make a wide variety of changes to a field.
The Bulk Replace tool functions much the same as the "Find and Replace" or "Replace" tools found in many word processors. It was designed to allow you to make a single change to a field. The Setup button opens up a dialog box that has a number of useful options. You can also use regular expressions to make complicated changes or to condition the change you want to make.
The Bulk Replace tool has many applications. You can use it to make a single change to your orthography. You can add an affix to a vernacular form or delete the affix. You can replace a space in your Gloss field with a period or an underscore character. If you have any systematic change that needs to be made, you can use Bulk Replace to do it.
To add a prefix to a form, type a caret (^) in the Find what: box and click Use Regular Expressions. (The caret (^) is the regular expression symbol that represents the beginning of the word.) Then type the prefix in the Replace with box.
To add a suffix, type a dollar sign ($) in the Find what: box and click Use Regular Expressions. (The dollar sign ($) is the regular expression symbol that represents the end of the word.) Then type the suffix in the Replace with: box.
To add something to an empty field, type ^$ in the Find what: box and click Use Regular Expressions. The caret (^) finds the beginning of the field and the dollar sign ($) finds the end of the field. So the regular expression means "find a field in which the beginning of the field is followed by the end of the field." In other words, find a field in which there is nothing between the beginning of the field and the end. Then in the Replace with: box type whatever you want to add to the empty field.
The Delete tool was designed to delete the contents of a field or to delete whole entries. You can also use it to delete senses. You should use this tool with extreme caution because it will delete data from your database. I would recommend that you make a backup of your project before using it.
The Delete tool is especially useful when you are trying to fill in a field using one of the Bulk Edit tools, but you made a mistake in the process and the results are not correct. You can use the Delete tool to delete the contents of the field and start over again. The Delete tool is also useful for deleting duplicate senses and entries. This sometimes happens when you merge two dictionaries.
The Reversal Indexes area (and the Bulk Edit Reversal Entries area) are designed to help you produce a reversal index for a bilingual dictionary. If you have more than one analysis language, you can produce an index for each one.
The Reversal Indexes area has two panes. On the left the Reversal Index pane shows how the reversal index might look in print. On the right the Reversal Entry pane enables you to edit a single index entry.
You can choose what fields to include in the index by using the Configure Reversal Index tool found under the Tools menu. In Language Explorer a reversal index entry consists of three fields. The Reversal Form field is the analysis language form that you gave in the Reversal Entries field in the Lexicon Edit area. So the Reversal Form field and the Reversal Entries field are really the same thing.
The Reversal Category field is intended to be the category of the analysis language word, not the vernacular word. If the analysis language form is not a single word, you should not give any grammatical category for it. If it is an idiom, you might want to considering labeling it as such. But some forms will simply be a description of the meaning of the vernacular word. It would be misleading to give a grammatical category for something that is essentially a definition. You should be especially careful when the grammatical category of the analysis language form and the vernacular form do not match. Because of these difficulties, most dictionaries avoid the whole problem by not even giving the grammatical category of the analysis language form. After all, the Reversal Index is an index to the dictionary, not a dictionary itself. However some users appreciate knowing the grammatical category of the analysis language forms. This is especially true of speakers of the vernacular who want to use your dictionary to learn the analysis language.
The Referenced Senses field is a virtual field that is automatically generated by Language Explorer. It is essentially a cross-reference to a sense of an entry in the lexicon. You can use the Configure Reversal Index tool to specify what will be included in the Referenced Senses field. Language Explorer can include any of the fields from the lexicon in the Referenced Senses field.
You can use the reversal index system to produce a simple index (also known as a "finder list") or to draft an analysis language-vernacular dictionary. Language Explorer is not designed to handle both sides of a vernacular-analysis and analysis-vernacular pair of dictionaries. To do an adequate job of producing both dictionaries, you would need to set up two separate projects.
The Bulk Edit Reversal Entries area is like the Bulk Edit Entries area, except that you would use it to make systematic changes to reversal entries. Reversal entries only have three fields--Form, Category, and Senses. You use the List Choice tool to fill in or edit the Category field, since it is a list field. You use the other tools to edit the Form field. You cannot edit the Senses field, since it is a virtual field that is automatically generated by Language Explorer.
The Texts & Words area is designed to help you analyze texts and the words in them. It has three primary purposes:
The five sub-areas in the Texts & Words area display your textual data in various ways and help you accomplish specific tasks.
In addition to the five sub-areas, there is also a parser that can be accessed from the Parser menu. If you want to use the parser to help you analyze words, you must first turn it on. There is also a spell-checker available under Tools--Spelling.
The Interlinear Texts area is designed to enable you to create a text corpus and to interlinearize the texts. The area consists
of two panes. The Texts pane on the left is a list of the texts in your text corpus. You can add a new text to the corpus by clicking the  icon on the toolbar.
icon on the toolbar.
The Text pane on the right is where you work on a particular text. At the top is a box where you enter the title of the text. Below this is a series of seven tabs that represent various views and tools.
The Concordance area enables you to generate a concordance of a wordform from your text corpus. If you have interlinearized your texts, you can search any line for any wordform, allomorph, lexeme, or gloss. You specify what you want to find in the Specify Concordance Criteria pane at the top left. The concordance entries are displayed in the Concordance Results pane at the bottom left. You can look at the larger context in the Full Context pane on the right.
The Word List Concordance area is similar to the Concordance area, except that it is limited to generating a concordance of wordforms. You cannot use it to search for other kinds of forms. For instance you cannot use it to generate a concordance of a lexeme in order to see all the inflected forms of the lexeme. The Wordforms pane consists of a list of all the wordforms in your corpus. It is a browse view, which enables you to sort and filter on various fields in order to narrow your search. For instance one of the available fields is the Number in Corpus field that gives the number of times the wordform occurs in the corpus. By sorting on this field you can investigate the most frequent words first.
The Word Analyses area enables you to see all the analyses that you have given while interlinearizing texts and the analyses proposed by the parser. The ones that you have approved come first. This area also enables you to approve or disapprove of analyses. If the correct analysis is not displayed, you can use the Parse Current Word tool under the Parser menu to find out why.
The Bulk Edit Wordforms area allows you to use the Bulk Edit tools on the list of wordforms found in your corpus. The only two fields that you can edit are the Form field and the Spelling Status field. You can use the List Choice tab to efficiently change the spelling status of your wordforms so that the spell checking tool will either approve of a spelling or flag it as misspelled.
The Grammar area is where you specify various aspects of your grammar. Most of the sub-areas are used by the interlinearizer and parser, but a few are used in your lexicon.
The Category Edit area is where you list the grammatical categories that are used in your language. This list is used in several places in Language Explorer, including the Grammatical Category field in the Lexicon. It is also used in the Texts & Words area in the interlinear display in the Lex. Gram. Info line and the Word Cat. line.
Grammatical category used to be called 'part of speech' and still is by some linguists. But the term 'grammatical category' is more descriptive of the phenomenon. A grammatical category is a group of words that all function in the grammar in similar ways. Grammatical categories often have subcategories of words that behave in different ways. It is also helpful to remember that some members of a category may behave in special ways morphologically, while others behave in special ways syntactically.
Each grammatical category in the list has a section for Affix Slots, Inflection Class Info, (Inflection) Features, and Stem Names. These sections enable you to specify how the category members behave morphologically. The sections were designed to be used by the parser, but some dictionaries also include this information in the dictionary article to help users know how to inflect words.
The Categories Browse area is merely a browse view of the data in the Category Edit area. You cannot edit in the Categories Browse area. So it is of limited usefulness except to line up each field in order to check for consistency.
The Compound Rules area enables you to list patterns of compounding for use by the parser. You need to do this if you want the parser to parse down to the root level. This area is not used by the lexicon. For more on compound rules see Introduction to Parsing under the Help menu.
The Phonemes area enables you to list all the phonemes in your language and all the orthographic representations of each phoneme. This is especially important if a phoneme has more than one orthographic representation. For instance in English the phoneme /k/ can be spelled 'c' or 'k' as in cat or kitten. Once you have listed your phonemes, they can be used in environments in the Environments area. This area is not used by the lexicon. For more on phonemes see Introduction to Parsing under the Help menu.
The Phonological Features area enables you to list the phonological features of your language. This area is not used by the lexicon. For more on phonological features see Introduction to Parsing under the Help menu.
The Natural Classes area enables you to list the natural classes of phonemes in your language. Once you have created an entry for a natural class, it can be used in environments in the Environments area. This area is not used by the lexicon. For more on natural classes see Introduction to Parsing under the Help menu.
The Environments area enables you to list various environments that constrain allomorphs. You use environments to constrain allomorphs in Lexicon Edit in the Allomorphs section of the entry. You can also give an environment for the default allomorph (which is put in the Lexeme Form field). For more on environments see Introduction to Parsing under the Help menu.
The Phonological Rules area enables you to list phonological rules needed by the parser. This area is not used by the lexicon. For more on phonological rules see Introduction to Parsing under the Help menu.
The Ad hoc Rules area enables you to list ad hoc rules needed by the parser to constrain allomorphs. This area is not used by the lexicon. For more on ad hoc rules see Introduction to Parsing under the Help menu.
The Inflection Features area enables you to list the inflection features needed by the parser to constrain patterns of inflection. You specify the inflection features of lexemes in Lexicon Edit in the Grammatical Information Details section of the entry. For more on inflection features see Introduction to Parsing under the Help menu.
The Exception "Features" area enables you to list the exception features needed by the parser to constrain patterns of inflection. You specify the exception features of lexemes in Lexicon Edit in the Grammatical Information Details section of the entry. For more on exception features see Introduction to Parsing under the Help menu.
The Grammar Sketch is a tool that will automatically draft a grammar sketch of your language based on the information that you have given in various places in Language Explorer. The tool gleans information from the Lexicon area, the Grammar area, and the Lists area. It uses a template and inserts the information it has gleaned into sections of the template. You can regenerate the grammar sketch periodically. Each time you regenerate the grammar sketch, Language Explorer updates all the information it has collected. It overwrites the old grammar sketch. You can edit the grammar sketch, but if you do, you should save the file to a different name. Otherwise Language Explorer will overwrite your changes the next time it regenerates the grammar sketch. The best strategy is to refrain from making any changes to the file until you are ready to publish it. At that point you should regenerate the sketch and save it to another name.
One purpose of the grammar sketch is to indicate residue and other problems with your project. You should periodically regenerate the sketch and check it for problems that need to be fixed.
This Problems area lists problems with the environments you have created in the Environments area. If you create an environment that is not well-formed, Language Explorer will copy it into the Problems area and generate an error report that explains what the problem is. The environment is copied into the Records column and the error report is placed in the Problem Report column. This enables you to diagnose the problem and fix it. Once you have fixed the problem, you should delete the record with its problem report.
The Lists area consists of a series of authority lists. These lists are used in various places in Language Explorer, mostly in the Lexicon, but in other places too. Each list field in Lexicon Edit corresponds to a list either in the Grammar area or the Lists area. For instance the contents of the Semantic Domains field in Lexicon Edit is chosen from a list of semantic domains. That list is maintained here. The lists are also used throughout the FieldWorks suite of programs. Some of the lists are used much more frequently in other applications, such as Data Notebook, and have limited usefulness in Language Explorer.
This list is used in the Academic Domains field in Lexicon Edit. For more on using academic domains see section 6.2.2.21.
This list is used in the Anthropology Categories field in Lexicon Edit. It is a sense level field and is used to classify a sense of a word that is relevant to some topic in anthropology. The list is the famous Outline of Cultural Materials (OCM), also known as the Human Relations Area Files (HRAF). It was originally developed by anthropologists as a system for filing field notes.[10]
This list is used in the Complex Form Type field in Lexicon Edit. It is an entry level field and is used to label different kinds of complex forms. A complex form is a lexeme that consists of more than one morpheme. If a lexeme is a complex form, you should indicate what type it is using the Complex Form Type field. Language Explorer uses this field to help the parser analyze words and phrases. It also uses it to format your printed dictionary. If you have been using Language Explorer for some time, you will recognize that this list partially replaces the old Entry Type list. (The other Entry Types are handled by the Variant Types list.)
This list is used in the Confidence field in some of the lists in the Lists area. If you add an item to one of these lists, you can indicate how confident you are of its validity.
The Text Chart Markers list is used in the Texts & Words--Interlinear Texts--Text Chart area. If you move the cursor over one of the cells in the chart, a blue menu arrow appears. If you click on the blue menu arrow, you can select one of the items from the Text Chart Markers list and it will be added as an annotation to that cell. For instance if a verb tense has more than one discourse function,
you can list each function in the Text Chart Markers list. Then in your text chart you can specify the function of the tense of a particular verb by selecting the appropriate
list item from the menu.
The Text Constituent Chart Templates list enables you to create a set of columns to use in the Texts & Words--Interlinear Texts--Text Chart area. Each item in this list corresponds to a column in your text charts. The list is hierarchical, so you can create major columns and sub-columns within each major column. You can only create one template.
The Education Levels list enables you to create a list of education levels. It corresponds to the Education field in the People list. You would use it to indicate the education level of each person in the People list.
The Feature Types list is used by the Inflection Features list in the Grammar area. It is not used in the lexicon. For more on feature types see Introduction to Parsing under the Help menu.
The Genres list enables you to list the various kinds of text genres in your text corpus. You use this list in the Texts & Words--Interlinear Texts--Information tab. It corresponds to the Genres field there.
The Lexical Relations list enables you to create a list of lexical relations that you want to use to cross-reference entries in your dictionary. The Lexical Relations list is used by two fields in the lexicon--the entry level Cross References field, and the sense level Lexical Relations field.
The Locations list enables you to create a list of locations in your language area. For instance you can list dialects, districts, or towns. The Locations list corresponds to the Place of Birth and the Place of Residence fields in the People list. You would use it to indicate the birthplace and current home of each person in the People list.
The Morpheme Types list contains a list of all the types of morphemes that have been identified by linguists. You cannot edit this list, since it is considered to be a complete listing of all possible morpheme types. It correspond to the Morph (Morpheme) Type field in the lexicon.
The People list enables you to create a list of people that are involved in your project. The People list corresponds to the Researchers field in many of the other lists in the Lists area, such as the Academic Domain list and the Anthropology Categories list. The People list is not used in the lexicon.
The Positions list enables you to create a list of professional positions in your project, such as Editor, Consultant, or Researcher. It corresponds to the Positions field in the People list. You would use it to indicate the role each person in the People list has in your project.
The Restrictions list enables you to create a list of restrictions on your data. From the default values it appears that the values relate to publishing concerns. However this list is only used in other lists and it would be highly unlikely that anyone would ever publish any of the lists. So it is unclear (to me) why anyone would use this list. It is not used in the lexicon. This list corresponds to the Restrictions field in many of the lists in the Lists area.
This list should not be confused with the Restrictions field in the lexicon. The two are not related.
The Semantic Domains list enables you to create a list of semantic domains that you can use to classify the lexemes in your dictionary. The list corresponds to the Semantic Domains field in the lexicon. The list of semantic domains is also used in the Collect Words area and the Classified Dictionary area.
Language Explorer is distributed with a list of domains already installed. This list is the Dictionary Development Process (DDP) list of domains. You can find out more about using semantic domains by visiting the DDP website (http://www.sil.org/computing/ddp/index.htm). You can edit the list to make it more relevant to your language and culture.
The Sense Status list enables you to create a list that describes various status levels of a sense. For instance you can indicate whether an editor has approved the sense for publication. The list corresponds to the sense level Status field in the lexicon. The development of a dictionary may span several years or decades. A researcher may work on an entry, doing research, filling in fields, and writing definitions. This field enables each researcher or editor to indicate how much work has been done on the sense, who has checked it, and whether it is ready for publication. The Sense Status field should not be confused with the Status field in the Lists area.
The Sense Types list enables you to create a list of sense types that you can use to label senses in your dictionary. It corresponds to the sense level Sense Type field in the lexicon. The default values are primary and figurative, but you can use it to be more specific. For instance you could use it to indicate the conceptual metaphor that a sense is based on.
The Status list enables you to create a list that describes various status levels. The list corresponds to the Status field that is used in many of the lists in the List area. It is not used in the lexicon. The Status field should not be confused with the Sense Status field.
The Text Markup Tags list enables you to create a list of tags to use in marking the syntactic constituents of a sentence in a text. You use this list in the Texts & Words--Interlinear Texts--Tagging tab.
The Translation Types list enables you to create a list of translation styles that you would use to label the translations of example sentences in your dictionary. If you give more than one translation of an example sentence, you can label each one to indicate what kind of translation style it uses. This is especially useful if you need to give both a literal translation and a free translation of an example sentence. This list corresponds to the Type field in the Example bundle of fields in the lexicon.
The Usages list enables you to create a list of social situations that you can use to indicate pragmatic restrictions on the usage of a sense in your dictionary. It corresponds to the sense level Usages field in the lexicon. If a sense of a lexeme is restricted in its usage, you should try to determine what factor restricts its usage and add that factor to this list. You can also use this list for other aspects of the usage of a sense, such as when a sense is rare or archaic.
The Variant Types list enables you to create a list of types of variants and irregularly inflected forms. It corresponds to the Variant Type field in the Variants section of the entry. If you have been using Language Explorer for some time, you will recognize that this list partially replaces the old Entry Type list. (The other Entry Types are handled by the Complex Form Types list.)
You should create an item in this list for each kind of variant. The list is hierarchical. So you can create a list of dialects under a major heading 'Dialectal Variant'. You can do the same for other kinds of variants, such as register variants.
This version of Language Explorer lumps irregularly inflected forms together with variants. So you will need to create a list item for each of them. I would recommend that you create a list item for each type of irregularly inflected form under the major heading 'Irregularly Inflected Form' (or perhaps 'Inflectional Variant'). For instance for English you would need a list item for irregular plural forms of nouns (e.g. men), irregular past tense forms of verbs (e.g. broke), and irregular past participles (e.g. broken). If you have a highly inflected language, it might be difficult to create enough list items to sufficiently label each irregular form. Unfortunately there is no other way to label irregularly inflected forms so that the labels can be used by Language Explorer in its system of cross-referencing minor entries.
The Reversal Index Categories list is used in the Lexicon--Reversals Indexes area to indicate the grammatical category of reversal index words. So it is a list of analysis language grammatical categories. It corresponds to the Category field. Note that the Category field in the Reversals Indexes area is the grammatical category of the analysis language word, not the vernacular word. The grammatical category of the vernacular word is automatically supplied from the lexicon. The list of vernacular grammatical categories is maintained in the Grammar-Category Edit area.
When linguists and lexicographers analyze lexical information, it is clear that there is structure in how the information is organized. There is structure in the mental lexicon, structure in a computerized dictionary database, and structure in a published dictionary. In order to make Language Explorer a more powerful program and in order to make the publication of a dictionary more straightforward, it was necessary to standardize the structure of the lexical database within Language Explorer. It is also necessary to standardize the structure of published dictionaries to some degree, while permitting as much freedom as possible. Doing so makes your job much easier.
Because of this, Language Explorer has established an underlying structure for lexical information within the program. This structure is reflected in what you see in the Lexicon-Entry pane. You cannot change the order of the fields in Lexicon-Entry view. However you can change the order of the fields in any of the browse views in order to bring together information that you want to compare. The structure of information in Language Explorer is very complicated and detailed. It is not necessary for you to understand all the details. However, if you are interested, I have described some of the more important aspects of the structure in section 6.1.
Language Explorer has also established a default structure for a published dictionary. This is what you see in the Dictionary area and in the top right pane in the Lexicon Edit-Entry pane. However you can change the ordering of the fields and how they are formatted in these dictionary views by changing the settings in the Configure Dictionary dialog box. You access this in Lexicon Edit under the Tools menu.
There are good reasons to enforce a logical structure on lexical data in a database. The biggest benefit to you is that you no longer need to worry about what order the fields should be in or what fields are subordinate to others. This enables you to concentrate on the data itself.
Other dictionary software (such as Toolbox) does not enforce structure on the data. This permitted a great deal of freedom, but resulted in serious problems whenever you needed to use or manipulate the data in any way. For instance printing a dictionary that is not correctly structured results in serious errors in the printout. (For more on this subject see section 2.1.4.) To solve these sorts of problems, the team that designed Language Explorer developed a linguistically sound data structure. This enables the program to do linguistically sophisticated tasks. When you enter data into the lexicon, it is automatically structured for you. You can still format the data in various ways for publication, but the data itself is stored using the standardized structured.
The data structure in Language Explorer assumes that the data relates to a single language (with allowance for dialectal variants). If you want to create something like a comparative dictionary that has a very different underlying structure, you will have to use a program like Toolbox that permits you to structure the data in any way you want.
The mental dictionary has a very complicated structure. However for practical reasons a dictionary database must be organized on the same basis as a published dictionary--around the lexeme form. So the critical field in Language Explorer is the Lexeme Form field. The database is in the form of records. Each record consists of a single lexeme and each record is headed by the Lexeme Form field.
A dictionary entry is basically organized as a hierarchy. However it is a little more complicated than that. The article is divided into two primary parts--those fields that relate to the entry as a whole, and those that relate to a single sense. So Language Explorer has a section for entry level fields and another section for sense level fields. But an entry can have more than one sense. Each sense contains a set of fields that form a bundle. So there can be more than one set of these fields in an entry. Some fields only occur once per entry or once per sense, while others can be repeated.
There are several fields on the entry level that can occur more than once. If you specify the Entry Type as either Derivative, Compound, or Phrase, you can link the entry to more than one root or affix in the Components field. You can specify more than one pronunciation for an entry. Each Pronunciation field comes with an associated CV Pattern field, Tone field, and Location field. These four fields form a bundle. You can specify more than one cross-reference in the Cross References field.
There are also several fields on the sense level that can occur more than once. You can add more than one example sentence in the Example field. Each Example field comes with an associated Translation field, Type field, and Reference field. These four fields form a bundle. You can specify more than one usage feature in the Usages field. You can create more than one reversal entry in the Reversal Entries field. You can specify more than one academic domain in the Academic Domains field. You can specify more than one semantic domain in the Semantic Domains field. You can specify more than one anthropology category in the Anthropology Categories field. You can specify more than one lexical relation in the Lexical Relations field.
The mental lexicon forms links between various linguistic forms. Language Explorer enables you to capture these links in various ways. You can cross-reference lexemes using the Components, Cross References, and Lexical Relations fields. You can capture groups of related lexemes using the Semantic Domains, Academic Domains, and Anthropology Categories fields.
A single lexeme may have variants. You capture these in the Variants section of the entry. You can add more than one variant. Each Variant Form field comes with an associated Variant Type, Show Minor Entry, and Comment field. These four fields form a bundle.
A single lexeme may have inflected forms. There is no systematic way to capture all the potential inflected forms of a lexeme. (There may be hundreds or even thousands in highly inflected languages.) However you can capture irregularly inflected forms in the Variants section of the entry.
A single lexeme may have more than one allomorph. You capture these in the Allomorphs section of the entry. You can add more than one allomorph in the Affix Allomorph or Stem Allomorph field. (The name of the field changes depending on whether the lexeme is an affix or stem.) Each Allomorph field comes with an associated Is Abstract Form, Morph Type, Environments, and Stem Name field. These five fields form a bundle.
The reason why there is a separate Grammatical Info Details section at the bottom of the Entry pane is because an entry can have more than one sense and each sense can belong to a different grammatical category. Each grammatical category used in the entry is displayed in the Category Info field in the Grammatical Info Details section. You indicate the grammatical category of a sense in the Grammatical Info field within the sense. If you need to further specify the grammatical category by indicating its inflection class, inflection features, and exception "features", you do this in the Grammatical Info Details section. This bundle of four fields is then available to be assigned to other senses. The way this all works is explained more fully in section 6.2.2.4.
In this section each field is briefly described. The description focuses on the nature of the field, the contents of the field, and the purpose of the field. You can find more information on each field in the Help files by searching for the field name. You can also right click on a field name in the Lexicon Edit-Entry pane and then choose Help from the menu.
The entry level fields form the first part of the entry in the Lexicon Edit--Entry pane. The information in these fields applies to the entire entry.
The Lexeme Form field is used to record the underlying or basic form of the lexeme. If the lexeme can be inflected, you would enter the uninflected form of the stem in this field. If you wish to use an inflected form of the lexeme as the headword in the published dictionary, you would put that form in the Citation Form field. If there is nothing in the Citation Form field, the contents of the Lexeme Form field will be used as the headword. If the lexeme has allomorphs, you would enter them in the Alternate Forms section. If the lexeme has variants, you should indicate them in the Variants section. If you wish to record inflected forms of the lexeme, you should create a Custom field for each paradigm form (e.g. the plural of a noun or the past tense of a verb). The Lexeme Form field should be reserved for the underlying, basic, uninflected allomorph, root, or stem. Since lexemes can be more than one word, you can enter lexical phrases into the Lexeme Form field.
Many languages require the use of an inflected form as the headword of the dictionary entry. When collecting words, native speakers will often supply the word in its citation form rather than as an uninflected stem. For instance the Dictionary Development Process word collection method uses native speakers to collect words. These are typed into the computer using the Collect Words tool. The lexemes automatically go into the Lexeme Form field, whether they are uninflected stems or inflected citation forms. If you find that the Lexeme Form field contains many inflected citation forms, you can use the Bulk Edit tools to copy the inflected forms into the Citation Form field and then delete the affixes from the form in the Lexeme Form field. For instructions on how to do this see section 4.2.8.
The contents of the Lexeme Form field are used by the parser. If it is an abstract form (i.e. not an orthographic form that occurs in texts), you must indicate this in the Is Abstract Form field so that it will not be used by the parser.
When importing data from an existing dictionary that was created using another program, sometimes an error occurs and nothing is imported into the Lexeme Form field. If this happens, you should immediately fill in the field with the correct form. So the Lexeme Form field should always have something in it. The Lexeme Form field is critical for many of the functions in Language Explorer.
The Is Abstract Form field is a toggle switch indicating whether the lexeme form is an abstract form or an orthographic form. An example of an abstract form would be 'iN-', an abstract representation of the English morpheme which has the two orthographic forms 'in-' and 'im-', as in 'incomplete' and 'impossible'. In this example 'iN-' would be entered in the Lexeme Form field, and 'in-' and 'im-' would be entered in the Alternate Forms section. There is an Is Abstract Form field following each Allomorph field in the Alternate Forms section. All of the Is Abstract Form fields work the same way. If there is a check in the box in the Is Abstract Form field, this indicates the form is abstract. If there is no check in the box, this indicates the form is orthographic. The abstract form 'iN-' would be marked as an abstract form by clicking the box, while 'in-' and 'im-' would be marked as orthographic forms by leaving the box unchecked.
The Morph Type field is used to indicate the type of morpheme contained in the Lexeme Form field. Morphemes fall into two basic types--affixes and roots. The Morph Type field is used by the parser. Information from the Morph Type field will also be gleaned for use in the Grammar Sketch.
When you create a new entry in Lexicon Edit, the New Entry dialog box is displayed. You can indicate the morpheme type in the second line:
When you type the lexeme form into the Lexeme Form box, the program looks to see if the form is an affix or a stem. If you typed a hyphen at the beginning of the form (as in the example above), the program assumes it is a suffix and automatically picks 'suffix' from the list in the Morpheme Type box. If you type a hyphen at the end, it assumes it is a prefix. If you type a hyphen at the beginning and the end, it assumes it is an infix. If you type an equal sign, it assumes it is a proclitic or enclitic. If you type no hyphen or equal sign in the Lexeme Form box, the program automatically assigns the entry to the morpheme type 'stem'. However you can use the Morpheme Type box to manually change the morpheme type to one of the following options:
Notice that the options include the punctuation that you use in the Lexeme Form box to indicate the morpheme type. (These are called leading and trailing tokens.) If you use the correct punctuation (token), Language Explorer will automatically assign the lexeme to the correct morpheme type, saving you the step of indicating it in the Morpheme Type box.
Once you have created an entry, you can change the morpheme type using the Morph Type field in the Lexicon Edit--Entry pane. If you chose one of the affix options when you created the entry, you will only see the following options in the Choose Morpheme Type dialog box:
circumfix, infix, interfixing interfix, prefix, prefixing interfix, simulfix, suffix, suffixing interfix, suprafix
If you chose one of the stem options when you created the entry, you will only see the following options:
bound root, bound stem, discontiguous phrase, enclitic, particle, phrase, proclitic, root, stem
However you can select the Show all Types option at the bottom of the Choose Morpheme Type dialog box and all the options will be displayed.
If the lexeme is a derivative or compound rather than a single morpheme, you should select 'stem' from the list of options. If the lexeme is a lexical phrase, you should select 'phrase' from the list of options. For instructions on using the Bulk Edit tools to fill in the Morph Type field see section 4.2.2.
You can see a list of all the morpheme types in the Morpheme Type list in the Lists area. You cannot add or delete items from the list, but you can edit the fields. For instance you can change the leading and trailing tokens.
The Environments field is used to indicate the phonological environment of an allomorph. The Environments field is used by the parser. Instead of typing out an environment, you pick the environment from a list of possible environments. The list is maintained in the Grammar--Environments area. You can create as many environments as you need. Once you have created an environment, you can use it to condition any number of allomorphs. If you create an environment for an allomorph of one morpheme and then find that an allomorph of another morpheme uses the same environment, you can reuse the environment you created for the first allomorph. You can pick more than one environment from the list.
The Stem Name field is used to label an allomorph that is conditioned by a grammatical context rather than a phonological context. The Stem Name field is used by the parser. You create a stem name in the Grammar--Category Edit area. For more on the Stem Name field see Andy Black's paper 'Introduction to Parsing' under Resources in the Help files menu.
The Citation Form field is used to record the form of the lexeme that you want to appear as the headword in a published dictionary. You would use the Citation Form field when the stem form of the lexeme (which you would put in the Lexeme Form field) is not a naturally occurring word and you do not want to use it as the headword. If the uninflected stem is not a good choice for the headword and you would prefer an inflected form, put the uninflected stem in the Lexeme Form field and the inflected form in the Citation Form field. Language Explorer uses the contents of the Citation Form field as the headword in Dictionary view. If there is nothing in the Citation Form field, it will use the contents of the Lexeme Form field as the headword. The parser uses the Lexeme Form field, but ignores the Citation Form field. For more on the difference between the lexeme form and citation form see section 3.3.3.
If your language requires the use of an inflected form as the headword, you will very likely find that you are collecting words in the citation form rather than the uninflected stem. If you enter these inflected forms into the Lexeme Form field, you will have to copy them into the Citation Form field and then correct the Lexeme Form field by deleting the affixes. For instructions on how to do this see section 4.2.8.
The Headword field is used to display the form of the lexeme that will be used as the headword in the publication views. It cannot be displayed in the Lexicon Edit--Entry pane. However it can be displayed in the various browse views. Language Explorer uses the contents of the Headword field as the headword in each of the publication views (Dictionary view, Classified Dictionary view, and Reversal Indexes view). It is also used in various search functions, such as the Main Entries or Senses dialog box. Cross-references use the headword to refer to another entry.
You cannot edit the contents of the Headword field because the contents of the field are taken from either the Lexeme Form field or the Citation Form field. Language Explorer automatically copies the contents of the Citation Form field into the Headword field. If there is nothing in the Citation Form field, it copies the contents of the Lexeme Form field. So the citation form takes priority over the lexeme form. If you want to change the headword, you must edit the citation form or the lexeme form. For more on the difference between the lexeme form, citation form, and headword see section 3.3.4.
The Dialect Labels (Entry) field is used to specify that an entry only pertains to certain dialects. It is a list field, and the values may be created in the Dialects list in the Lists area.
The Complex Forms field is used in an entry for a root to list all the complex forms that you have linked to the root. It is a virtual field, meaning that you do not enter data into it. Instead Language Explorer automatically puts something into the field whenever you link a complex form to the root. The field is merely for your convenience and information. You can right-click on one of the entries listed and jump to the entry or to a concordance of the entry. Language Explorer uses the list to format your published dictionary. Depending on the choices you make in Tools-Configure Dictionary, it will create a subentry or cross-reference for each lexeme listed here.
If a lexeme is a complex form (a derivative, compound, or lexical phrase), you use the Complex Form Type field to specify what kind of complex form it is. A complex forms is any lexeme that is composed of more than one morpheme. For instructions on using the Bulk Edit tools to generate the Complex Form Type field see section 4.2.3.
You maintain the list of complex form types in the Lists--Complex Form Types area. You can create new complex form types in the Complex Form Type pane.
The Components field is used to link a complex form to its root (or roots). You can also link a derivative to its derivational affixes. Currently you cannot link a complex form to another complex form. For instance you could not link incurable to curable. You would have to link it to its root cure. In other words you can only link a complex form to its constituent morphemes. If you link a complex form to another complex form, Language Explorer will not display the entry anywhere in your dictionary.
In a root-based dictionary each complex form is presented as a subentry under one of its roots. If a complex form has more than one root, you use the Show Subentry under field to specify which root you want the subentry to appear under. You must first link the complex form to its roots in the Components field. You can choose more than one root, but this will have the effect of duplicating the subentry under each root.
In a root-based dictionary each complex form is presented as a subentry under one of its roots. If it would be difficult for the user to find the entry, you can create a minor entry for the complex form. The minor entry will alphabetize where the complex form would have appeared in a lexeme-based dictionary, making it possible for the user to look up the spelling of the complex form. For instance the root of prospective is spec, the root of prosthesis is thesis (or the), and the root of prototype is type. Because of the difficulty in knowing how to analyze these forms, it would be necessary to create a minor entry for each to direct the user to the correct root entry.[11] The Show Minor Entry field is used to indicate whether or not you want Language Explorer to generate a minor entry for the complex form.
The Comment field is used to record a note to yourself about your handling of a complex form. This field should not be confused with other Comment fields, such as the one in the Variants section and the one in the Etymology section. All three are note fields for the relevant section.
If the current entry is a variant of another entry, you would use the Variant Type field to indicate what type of variant the current entry is. This field only shows when you have indicated that the current entry is either a variant of a basic form or an irregularly inflected form of a lexeme. The Variant Type field is a list field. The list is maintained in the Lists-Variant Types area. This field corresponds to the Variant Type field in the Variants section toward the bottom of the Entry pane. For instructions on handling variants see section 3.2.2.
If the current entry is a variant of another entry, you would use the Variant of field to link the current entry to the entry for the basic form. If you created the current entry using the Variant section of the basic form entry, then this field will already be filled in.
This field is the reverse of the Variant Form field in the Variants section of the basic form entry. The two fields form the opposite ends of the link between the two entries. The Variant of field contains the basic form and the Variant Form contains the variant. For instructions on handling variants see section 3.2.2.
Use the Show Minor Entry field to indicate whether or not you want Language Explorer to create a minor entry for this variant. This field corresponds to the Show Minor Entry field in the Variants section toward the bottom of the Entry pane. For instructions on handling variants see section 3.2.2.
The Comment field is used to make a note to yourself about the variant in the Variant Form field. This field should not be confused with other Comment fields, such as the one in the Complex Form section and the one in the Etymology section. All three are note fields for the relevant section.
The Pronunciation field is used to record the pronunciation of the headword, usually by transcribing it phonetically in the International Phonetic Alphabet (IPA). Since the IPA is often not understood or useable by non-linguists, sometimes the pronunciation is indicated in a modified orthographic script. In a monolingual dictionary designed for native speakers this is often a good choice. Native speakers may not need a detailed phonetic transcription, but may benefit from an indication of features of the phonology that are not captured by the standard orthography. For instance many monolingual English dictionaries indicate stress. If your language has lexical tone or stress, which is not marked in the orthography, you can use the Pronunciation field to indicate it. The Pronunciation field can also be used to indicate syllable breaks for use in hyphenating words at the end of a line of text. If, on the other hand, you are producing a bilingual dictionary that will be used for learning the vernacular language, you should probably use IPA in the Pronunciation field, since IPA is becoming a standard in the international language learning community.
In order to save space some lexicographers eliminate the Pronunciation field and instead use the headword to mark stress, tone, or other features. Other lexicographers prefer to use the headword to indicate the orthographic representation of the word. If your language is newly literate and you want the dictionary to be used to promote literacy and teach people how to write the language, then it would be best to use the headword to give the spelling of the lexeme using the proposed orthography. In this case you would need to use the Pronunciation field to indicate any features of the pronunciation that are not captured by the orthography.
The Pronunciation field is also used to record dialectal pronunciation variants. If you have a standardized orthography that is used by several dialects, you would record dialectal variants here. Only when a variant is spelled differently would you need to create a separate entry for it in Language Explorer. If the variants are spelled the same, you would have to use the Pronunciation field for them. For instructions on using the Bulk Edit tools to generate the Pronunciation field see section 4.2.9.
The CV Pattern field is used to record the consonant-vowel pattern of the form in the Pronunciation field. There is a CV Pattern field for each Pronunciation field, since the CV pattern may be different for each pronunciation. You create the CV Pattern field by copying the contents of the Pronunciation field into the CV Pattern field and replacing each consonant with a 'C' and each vowel with a 'V'. You can further refine the pattern by using other symbols such as 'S' for semivowel or 'N' for nasal, if these affect the syllable structure or phonology in significant ways. In fact you can be creative in the use of the CV Pattern field to meet your needs. The CV Pattern field is very useful for various tasks in phonological analysis. For instance tone patterns are often affected by the CV pattern of the word. So it is helpful to be able to sort words by their CV pattern. The CV Pattern field is not used by the parser and would not normally be included in a published dictionary. It is including in Language Explorer as an analysis tool. For instructions on using the Bulk Edit tools to generate the CV Pattern field see section 4.2.10.
The Tone field is used to record the tone or stress pattern of the form in the Pronunciation field. There is a Tone field for each Pronunciation field, since the tone pattern may be different for each pronunciation. You create the Tone field by copying the contents of the Pronunciation field into the Tone field and replacing each consonant with a period (or simply nothing) and each vowel with an 'H' for high tone and an 'L' for low tone'. You can use other symbols such as 'F' for falling tone or 'R' for rising tone. You can also use numbers or any other symbols you want. This assumes that tone is already marked in the Pronunciation field. If you have not marked tone, you can use the Tone field to enter it. However it is wiser to mark it in the Pronunciation field and then use the Bulk Edit tools to generate the Tone field. The Tone field is not used by the parser and would not normally be included in a published dictionary, although it could be. It is including in Language Explorer as an analysis tool. For instructions on using the Bulk Edit tools to generate the Tone field see section 4.2.11.
The Tone field is not used by the parser and would not normally be included in a published dictionary, although it could be. It is including in Language Explorer as an analysis tool. Some languages have tone processes that modify the underlying tone of a stem when it is affixed or when it occurs in isolation (when it is pronounced by itself). In such cases you might want to indicate the underlying tone of the stem in one field and the surface tone of the citation form in another field. Since the Tone field is subordinated to the Pronunciation field, it would be best to use it to indicate surface tone and set up a custom field on the entry level for the underlying tone.
The Location field is used to indicate the location where a pronunciation variant is used. For instance if you have a standardized orthography that is used by several dialects, you would indicate dialectal pronunciation variants in the Pronunciation field. You would indicate the dialect in the Location field. The location is chosen from a list. The list is maintained in the Lists--Locations area. You can create as many locations as you need. These locations can be the names of dialects, districts, towns, or whatever other designation you wish. The contents of the Location field do not have to be a physical location. For instance if a particular pronunciation is a register variant, you can use the Location field to indicate the register.
The Etymology cluster is used to indicate various information about the origins of the word. For instance the English word 'name' is descended from the proto-Indo-European root 'nomen'.
[Needs updating:] Note that there is currently no field in Language Explorer specifically devoted to borrowed words. An expansion of the etymology section has been requested. Until the programmers can implement it, you can use the Etymology field to indicate borrowed words. However it would be wiser to set up a custom field for them in order to keep inherited words and borrowed words separate in the database. In order to fully specify a borrowed word, you could set up separate custom fields to indicate the source language, the form in the source language, and the original meaning in the source language.
The Preceding Comment field is used for whatever annotation you want to use before the proto-language form of the word. For instance you might use '<' or 'from' in this field.
The Source Language field is used to indicate the proto-language of the word. For instance the English word 'name' is descended from the proto-Indo-European root 'nomen', so you would enter proto-Indo-European here. The Source Language field is a list field and gets its values from the Languages list in the Lists area. The Source Language Notes field is a free-form field in which you may type whatever you wish. This is useful when you wish to include annotations on the language name, such as 'from Malay, probably'.
The Source Form field is used to indicate the proto-language form of the word. For instance the English word 'name' is descended from the proto-Indo-European root 'nomen'.
The Gloss field is used to indicate the meaning of the proto-language form given in the Source Form field. (Note that this Gloss field is different than the Gloss field on the sense level.) For instance the English word 'hell' is from the proto-Indo-European root 'kel'. But 'kel' originally meant 'to cover, conceal' Morris (1978). So you would enter 'to cover, conceal' in the Gloss field.
The Following Comment field is used for whatever annotation you may want to put at the end of an etymology. Unlike the Etymology Note field, this field is intended for printing.
The Source field is used to indicate the source of the information in the Etymology field. For instance the information about the etymology of the English word 'hell' in section 6.2.1.27 was taken from the American Heritage Dictionary on page 1521. So I would put something like "AHD:1521" in the Source field. The Source field is adapted from the MDF "Etymology Source" field, which in that system was a note field and not intended for printing. If you use a published work to find information about the etymology of words, you should indicate this in your introduction and include a reference to it in your bibliography. If you do this, it would not be necessary to print the Source field in your dictionary. This field should not be confused with the Source field on the sense level.
The Etymology Note field is used to record any comments you might want to make about the etymology of the lexeme. The Etymology Note field is adapted from the MDF "Etymology Comment" field, which in that system was a note field and not intended for printing. It is included in Language Explorer so that you will have a place for notes to yourself to remind yourself of issues and factors related to your analysis. For instance in section 6.2.1.27 I mentioned that the English word 'hell' is from the proto form 'kel'. The evidence for this is that the Germanic form from which 'hell' is descended was 'haljō', which meant 'concealed place'. You could put this evidence in the Comment field.
If you are uncertain of the etymology of a word, you can discuss the options in the Etymology Note field. For instance 'name' is descended from 'nomen'. The word 'nominate' looks very similar to both 'name' and the Latin word 'nōmen', which also meant 'name'. If you didn't have good historical evidence, you might be uncertain if 'nominate' was descended from the proto-Indo-European 'nomen' or borrowed from the Latin 'nōmen'. (In fact it is borrowed from the Latin.) You could note the two possibilities and the pros and cons of each in the Etymology Note field.
This field should not be confused with other Comment fields, such as the one in the Complex Form section and the one in the Variant section. All three are note fields for the relevant section.
The Note field is used to make a note to yourself about any aspect of the entry. Since it is an entry level field, you should use it to make notes about the entry level fields. There are several note fields on the sense level to handle sense level issues.
The Literal Meaning field is used to indicate the literal meaning of a complex form. For instance the Koine Greek idiom 'kleiō ta splankhna' (κλείω τὰ σπλάγχνα) means 'refuse to show compassion', but literally means 'close the intestines'. Sometimes the literal meaning of a complex form can give a clue as to its meaning. For instance I have found it helpful to use the literal meaning of complex forms to identify conceptual metaphors. On the other hand, the original motivation for coining a word or phrase may be lost in history. In such cases the literal meaning may actually be misleading. For instance the literal meaning of understand seems to have nothing to do with standing under something. Some lexicographers believe that including the literal meaning in a bilingual dictionary will help a language learner "think" in the language. For instance the literal meaning of the English idiom hot under the collar 'to be angry' is based on the conceptual metaphor "Anger is heat and pressure" and refers to the tendency for a person's neck to turn red when he is angry. Understanding how the literal meaning and actual meaning are related can be helpful. On the other hand, studies have shown that a lot of vocabulary acquisition happens subconsciously. In either case, including the literal meaning of complex forms can be interesting.
The Bibliography field is used for a bibliographical reference to a book or article that discusses the lexeme. For instance a grammatical word might be discussed in a published grammar, or a culturally important word might be discussed in an anthropology paper. The contents of the Bibliography field can either be a short reference to an entry in the bibliography section of the published dictionary or a full reference if there is no bibliography in the published dictionary. This field is intended to be printed. There is also a Bibliography field on the sense level (see section 6.2.2.8).
The Restrictions field is an entry level field used to indicate grammatical, semantic, or pragmatic restrictions on all senses of the lexeme. This would enable you to avoid having to repeat the information for each sense.
The Summary Definition field is used for a single definition that summarizes all the senses of a lexeme. The field is used when you want to gloss a cross-reference in your published dictionary. You can configure Language Explorer to display the Summary Definition field in a published dictionary by going to Tools-Configure Dictionary. The Summary Definition field is available on the entry level under the Variant Forms section, the Cross References section, and the Component Reference section. It is available on the sense level under the Variants of Sense section. Following the sense level fields, it is available under the Complex Forms section. In order to use the Summary Definition field for all cross-references, you would have to enable it in each of these places.
The Exclude As Headword field is used to exclude an entry from the published dictionary. It does not just exclude the headword (as the name would suggest), but excludes the entire entry. Sometimes you may need to create an entry in your lexicon in order to interlinearize a word (such as a foreign word or name) in a text. You may also want to create entries for all your affixes, but not want them in the dictionary. In order to prevent such an entry from being displayed in your published dictionary, you should put a check mark in the box in this field. You can use Bulk Edit Entries-List Choice to exclude many entries at once.
The Cross References field is used to create a cross-reference between two entries rather than two senses. To create a cross-reference between two senses you should use the Lexical Relations field on the sense level. The Cross References field and the Lexical Relations field both use the same set of lexical relations. The list of lexical relations is maintained in the Lists-Lexical Relations area. Note that lexical relations are semantic relations and therefore properly belong on the sense level. In fact I don't know when you would ever use the Cross References field. A relationship on the entry level would be between two forms. In Language Explorer relations between forms are handled by the Complex Forms section and the Variants section.
When you import data into Language Explorer, any data that does not map into one of the Language Explorer fields will be placed in one of the Import Residue fields. If the data relates to the entire entry, it will be put into the entry level Import Residue field. If it relates to a particular sense, it will be put in the sense level Import Residue field for that sense. You can use Bulk Copy or Click Copy to move data from the Import Residue field to any field you choose.
The sense level fields form a bundle that can be repeated for each sense. The Entry pane always displays one sense in the Sense 1 section. You insert a second sense by clicking somewhere in the Sense 1 line and then clicking Insert Sense. You can also insert a subsense by clicking just to the left of the Sense 1 field label. This accesses a menu. Click Insert Subsense.
The Sense Number field is automatically filled in by Language Explorer. You can add senses, order senses, and create subsenses. Language Explorer automatically adjusts the sense numbers whenever you do one of these things. You can pick different numbering options by going to Tools-Configure Dictionary and then clicking on Senses. For more on managing senses see section 3.7.
The Gloss field is used to store a gloss in an analysis language. A gloss is a very short definition, usually consisting of a single word. A single word gloss in the vernacular would be a synonym. A single word gloss in another language would be a translation equivalent. Often it is not possible to capture the meaning of a lexeme with either a synonym or translation equivalent. If you need more than one word to capture the meaning, you can use a phrase. It is best to keep it as short as possible. If you want to give a long description that better captures the meaning, you should do so in the Definition field. The best way to think about a gloss is to view it as a short indication of the meaning, rather than an accurate explanation.
The Gloss field is used in three different ways in Language Explorer.
If you have set up more than one analysis language, you can enter a gloss for each language. Currently Language Explorer only permits a single gloss per analysis language. This creates problems when a single sense in the vernacular can be translated by several different words in an analysis language. When interlinearizing, some linguists prefer to give a gloss that fits the context. If you wish to do this, you can either give a more contextually relevant gloss in the Word Gloss line or give one in the Free (translation) line. The only other option is to give more than one gloss in the Gloss field and separate each one with some character such as a slash. For instance if you have a vernacular word that means 'sibling' you might want to give 'brother/sister' as the gloss.
If you give a gloss that consists of two or more words, the convention is to use a period or underline character (e.g. 'older.brother' or 'older_brother' to join the words into a single string of characters. The reason for this is that some programs line up an interlinear display on the basis of the spaces in the data. So using spaces in a gloss would mess up the alignment. This is not a problem in Language Explorer. It will correctly handle a gloss with spaces. However for clarity sake you might want to go by the convention. You can easily use Bulk Edit Entries--Replace to replace all spaces in the Gloss field with a period or underline.
The Definition field is used to describe the meaning of the word. If you do not give a definition, the program will use the Gloss field as the definition. You can give a definition in the vernacular or in any of the other analysis languages. The principles and techniques for writing good definitions are too many and involved to describe them adequately here. I've included a few basic principles in section 4.3.
Language Explorer handles 'part of speech' a little differently than you may be used to. The way a word functions in the grammar is more complicated than the traditional part of speech labels like 'noun' or 'verb' can capture. So the Lexicon Edit--Entry pane has a Grammatical Info Details section at the bottom that includes the Category Info field (which roughly corresponds to the traditional part of speech), Inflection Class field, Inflection Features field, and Exception "Features" field. For this reason the Grammatical Info field in the Sense section is related to the Grammatical Info section at the bottom of the entry. Each time you indicate a category in the Grammatical Info field it is listed in the Grammatical Info section. If you assign different senses to different categories, each is listed in the Grammatical Info section. You need to indicate the grammatical category for each sense. If more than one sense uses the same grammatical function, you can choose from the list of grammatical functions that you have already set up for the entry. The grammatical functions that you set up are recorded in the Grammatical Functions area at the end of the record in the Lexicon Edit-Entry pane. The Grammatical Function field under each sense is where you choose the grammatical function for that sense.
The senses of an entry often belong to the same grammatical category. Rather than have you reproduce all the information in the Grammatical Info section for each sense, Language Explorer enables you to give the grammatical information once and then assign it to each sense. You assign a grammatical category to a sense in the Grammatical Info field in the Sense section. You indicate the inflection class, inflection features, and exception "features" in the Grammatical Info Details section. This bundle then is available to assign to more than one sense. If different senses belong to different grammatical categories, you first indicate the grammatical category in the Grammatical Info field in the Sense section. Each grammatical category that you have used in the entry is listed in the Grammatical Info Details section. When you insert secondary senses, you can pick one of the category bundles that are listed in the Grammatical Info Details section. The master list of grammatical categories is maintained in the Grammar area.
The Example field is used to store an example sentence that illustrates the meaning and usage of the sense. When you are working on a sense and want to add an example sentence, you can use the Find example sentence tool to get a concordance of the word from your text corpus and copy a sentence into the Example field. You can access this tool by right clicking on the Example field label, then choosing Find example sentence from the menu.
The Scientific Name field is used to store the scientific names of plants, animals, chemicals, and other things for which modern science has a technical name. If you use the Scientific Name field, it would generally be printed after the Definition field, as in the following entry (adapted from the American Heritage Dictionary):
| (90) |
|
However many dictionaries incorporate the scientific name into the definition. The definition in the original American Heritage Dictionary entry was as follows:
| (91) |
|
This entry illustrates two problems with scientific names. First, the non-scientific word wolf actually covers more than one species. Second, scientists don't always agree on how to divide kinds of animals into species and subspecies, nor do they always agree on the correct name. The following entry illustrates a similar problem:
| (92) |
|
The word fox corresponds not just to a genus (a level above the species), but to related genera as well. It is difficult to capture this type of information in the Scientific Name field. You will have to decide on a strategy for handling scientific names. For straightforward cases you may be able to put the scientific name in the Scientific Name field. For more complex cases you will most likely have to discuss the situation within the Definition field. One advantage of using the Scientific Name field is that Language Explorer will automatically format it for you, for instance by putting it in italics as is in the examples above.
Identifying the scientific name of a plant or animal is not easy for non-experts. You will need to consult books and other resource materials that have photos of the plants and animals in your language area and that give reliable information on the appropriate scientific name. It would be best to obtain the help of a qualified biologist.
The Anthropology Note field is used to make notes to yourself about how the current sense relates to cultural issues. For instance you might use it to make a series of observations such as, "The color 'black' appears to be associated with bad things like evil 'black heart', bad feelings 'black mood', and death 'dressed in black'." You might also use it to make a note for further research such as, "Why is 'red' associated with anger?" Like the other note fields, it is not intended to be included in your published dictionary. However you can configure your dictionary to include it.
The Bibliography field is used for a bibliographical reference to a book or article that discusses the current sense. For instance a grammatical word might be discussed in a published grammar, or a culturally important word might be discussed in an anthropology paper. The contents of the Bibliography field can either be a short reference to an entry in the bibliography section of the published dictionary or a full reference if there is no bibliography in the published dictionary. This field is intended to be printed. There is also a Bibliography field on the entry level (see section 6.2.1.33). If you merely want to indicate the person or place where you got your information, you can use the Source field (see section 6.2.2.17). If the source is a previously published dictionary, you should get permission to incorporate it into your dictionary. If you have permission, there is no need to give a bibliographical reference for each entry. Instead you should give credit in the introduction to your dictionary and include the prior dictionary in the bibliography.
The Discourse Note field is used to make notes to yourself about how the current sense functions on a discourse level. You can use it to make a note for further research such as, "Does 'once upon a time' mean that the story is fictional?" Like the other note fields, it is not intended to be included in your published dictionary. However you can configure your dictionary to include it.
The Encyclopedic Info field is used to store information about the sense, which might be considered more appropriate for an encyclopedia than a dictionary. Some lexicographers prefer to write a definition that is succinct and place other information in the Encyclopedic Info field. Other lexicographers do not believe that there is any theoretical basis for dividing knowledge about a lexeme into "definitional knowledge" and "encyclopedic knowledge." Consider the following entry:
| (93) |
|
You might put "A musical instrument in the woodwind family, whose sound is produced by the vibration of a single reed," in the Definition field and put the rest of the description in the Encyclopedic Info field. However most people's conception of a clarinet would probably include the fact that it is black, has metal keys, and has a straight cylindrical shape with a bell shaped end. In contrast some people might not know that it has a single reed. I played the clarinet for 11 years in school but never knew what plant the reed was made of until I looked it up today on the internet.[12] So what information speakers have in their "mental definition" and what information is encyclopedic is subject to debate. Whatever your theoretical persuasion, you can use the Encyclopedic Info field for extra facts about the lexeme that you don't want to incorporate into your definition.
The General Note field is used to make general notes to yourself about the current sense. For instance you might use it to make an observation such as "This sense is more frequent than sense 1, but is obviously a metaphorical extension." Like the other note fields, it is not intended to be included in your published dictionary. However you can configure your dictionary to include it.
The Grammar Note field is used to make notes to yourself about how the current sense works in the grammar. For instance you might use it to record the fact that pants is always plural except in compounds such as pant leg. You could also use it to make a note for further research such as, "Why is this verb almost always passive?" Like the other note fields, it is not intended to be included in your published dictionary. However you can configure your dictionary to include it.
The Phonology Note field is used to make notes to yourself about the phonological behavior of the current sense. It is very rare for a lexeme to be pronounced differently depending on the sense. So perhaps this field should have been an entry level field. But you can still use it to make notes about the phonology. Like the other note fields, it is not intended to be included in your published dictionary. However you can configure your dictionary to include it.
The Restrictions field is where you would record semantic or grammatical restrictions on the usage of this sense of the lexeme. This is similar to the Usages field, except the Usages field is for sociolinguistic restrictions on usage. Some lexicographers prefer to incorporate this information into the definition and there are techniques for doing so. However if you have systematic restrictions on usage, it might be preferable to handle them here so that you can filter the database for them. This would help you handle them consistently.
This field corresponds to the \oe (Only) field in MDF. Unfortunately the MDF manual gives no clear examples of how this field should be used. However you could use it for grammatical restrictions such as "only in progressive aspect" (a restriction on some English verbs) or semantic restrictions such as "always with human subject and object" (also a restriction on some verbs). In the following example (adapted from Longman's Language Activator Summers (1993)) the phrase "usually before noun" is a grammatical restriction:
This field should not be confused with the Restrictions field in the Lists area. The two are not related.
The Semantics Note field is used to make notes to yourself about the meaning of the current sense. For instance if you have written a definition, but are not sure if it is accurate, you can make a note to yourself to check some aspect of it later. You can also use this field to make a series of lengthy notes about the meaning of a sense, then later compile them into a neat definition. Like the other note fields, it is not intended to be included in your published dictionary. However you can configure your dictionary to include it.
The Sociolinguistics Note field is used to make notes to yourself about the usage of the current sense. For instance you may be unsure if a sense is limited to a particular dialect or register. You could put a note to this effect in the Sociolinguistics Note field to remind you to investigate it further at a later date. Like the other note fields, it is not intended to be included in your published dictionary. However you can configure your dictionary to include it.
The Source field is used to indicate the source of the information in the current sense. It is often useful to know where you got your information. For example you can enter the name or initials of the researcher or the name of the town where the information was gathered. This might help you later to identify dialectal variants. You can also use the Source field to indicate that the sense was part of an earlier work such as a word list. If you have a bibliographical source for the information, you should put it in the Bibliography field (see section 6.2.2.8). The Bibliography field is normally included in the dictionary but the Source field is usually not included. If the source is a previously published dictionary, you should give credit in the introduction to your dictionary. There is no need to give a bibliographical reference in every entry in your dictionary, but you could indicate in the Source field that the current sense was in the prior dictionary. That way you can refer back to it to see what the original entry said.
The Usages field is used for labels that indicate the pragmatic or sociolinguistic factors that restrict how a lexeme is used. The following sociolinguistic factors can affect the usage of a lexeme. Your language may have some or all of them.
The Usages field is a list field. You may find that you need to describe the usage of a lexeme using a long phrase rather than a short label. It is possible to create a list item that consists of a phrase such as 'primarily used between men of the same age'. However, If you find that it is better to describe the usage of a lexeme in prose, or if you find that usage issues cannot be handled by a nice neat list, you may need to set up a custom field in which you can describe the usage more fully. Another alternative is to incorporate usage into the definition.
You should define each of your usage labels in the introduction to your dictionary. This is especially important if you have cultural or sociological factors that need to be explained to outsiders.
The Reversal Entries field is used to create an entry in the Reversal Index for a bilingual dictionary. You can create more than one reversal entry for a sense. For instance the Greek verb sōzō (σῴζω) can be defined as 'to rescue someone from danger (such as death, sickness, or hell)'. There are several words in English that could be used as translation equivalents for sōzō, including rescue, save, heal, and cure. However we have to be careful just putting these words into the Reversal Entries field. The Greek word sōzō and the English word can both be used in the frame "Someone sōzō/rescues someone from danger." The word sōzō can be used of saving a thing, but is almost always used of saving someone. The same is true of the English word rescue. So we can create a reversal entry for resuce without any qualification:
| (95) |
|
However the English word save has more than one meaning, as in the sentence, "I'm saving my money to buy a new computer." So we need to qualify which meaning of save is the equivalent of sōzō. We do this by using a phrase:
| (96) |
|
Note that we are not trying to define sōzō. We are merely clarifying which meaning of save is intended.
The word heal also has more than one meaning, as in "His wounds healed slowly." So again we need a phrase:
| (97) |
|
The word cure has a slightly different problem. The subject of cure is usually a form of treatment as in "The new drug cures tuberculosis." Notice also that the object in this sentence is a disease, not a person. But the word sōzō is used in the frame "Someone sōzō someone from (a disease)." To clarify this we need to use the phrase "for someone to cure someone from a disease." But we need to break it up so that cure comes first:
| (98) |
|
All of this would be entered into the Reversal Entries field as follows:
Once you have created reversal entries for all the words in your dictionary, you need to check to see if there are any that are identical on the analysis language side, as in the following two:
| (100) |
|
| (101) |
|
If the two vernacular words are different in meaning, it helps the user to know what the difference is. Otherwise they have to look up both to find the one they want. If you make things easy on the user, you will end up with happy users.
| (102) |
|
| (103) |
|
Use the following principles when developing reversal entries:
The Sense Type field is used to label different kinds of senses. Many lexemes have a basic sense and one or more figurative senses that have been created by metaphorical extension. For instance the basic meaning of family in English is 'a father, mother, and their children'. But it also has a secondary sense 'any group of things, especially plants, animals, or languages, that share characteristics or are considered to be derived from a common source'. The second sense could be given the label 'metaphorical extension'. Similarly the primary meaning of fly is '(for a bird) to use its wings to move through the air'. But it has a 'figurative' meaning 'to move quickly', as in "She flew by as if someone were chasing her."
There are several difficulties in labeling sense types. First, there does not seem to be a good theoretical basis for distinguishing between "literal" and "figurative" senses. There seems to be some basis for claiming that a sense that refers to a physical object, action, or quality is somehow more basic than a non-physical sense. So the meaning of slip in "His foot slipped," is considered to be more basic than "His standards have slipped."
The Academic Domains field is used to link the sense to one or more academic domains. It can be used to classify a sense of a lexeme that is relevant to some academic field. It is also an excellent way to label technical terms in your language and indicate what specialized field the term is used in. You can use the list of academic domains to classify all the words of your language. However there is a whole lot more to life than academics. So it would be better to use the list of semantic domains to classify your entire lexicon. The list of academic domains is maintained in the Lists-Academic Domains area.
The Semantic Domains field is used to link the sense to one or more semantic domains. The list of semantic domains is maintained in the Lists-Semantic Domains area. The list that comes packaged with Language Explorer is the Dictionary Development Process (DDP) list. It is the same list that is used in the Collect Words area.
There is a tool in the Choose Semantic Domains dialog box called Suggest. It will suggest possible semantic domains for the word, based on what you have entered in the the Gloss field.
The Anthropology Categories field is used to link the sense to one or more anthropology categories. The list of anthropology categories is maintained in the Lists-Anthropology Categories area. The list that comes packaged with Language Explorer is the standard Human Relations Area Files (HRAF), also known as the Organization of Cultural Materials (OCM), that is used to organize anthropology field notes and files. If you use the FieldWorks Data Notebook to record cultural observations, you can search both your notes in Data Notebook and your dictionary entries for information on one of the anthropology categories.
The Status field is used to label the status of the sense. Since the development of a dictionary frequently takes several years or even decades, it is useful to have some record of what work you have done on a sense or how much progress you have made. You can use this field to indicate who worked on the sense, whether or not you are happy with the work, whether it still needs to be checked, whether it conforms to your style guide, whether or not the sense is approved for publication, etc.
The Status field is a list field and the list is maintained in the Lists-Sense Status area. Do not confuse the Sense Status field with the Status field in the Lists area, which is used to indicate the status of list items.
The Lexical Relations field is used to link the current sense with a sense of another lexeme. There are various types of lexical relations. The two that are most familiar to people are 'synonym' and 'antonym'. The list of lexical relations is maintained in the Lists-Lexical Relations area. You can add to this list to meet your needs.
Linguists and lexicographers have noted for a long time that lexemes are related to one another in various ways. A number of linguists have proposed lists of commonly occurring lexical relations. For instance the pairs of words runner:run, builder:build, creator:create, cook:cook, pilot:fly are all related by the lexical relation Typical Agent:Activity. Note that some, but not all, of the nouns are derived by the addition of the derivational affix -er/-or. This is because the relation is semantic, not morphological. When we link lexemes together, we must be careful to analyze the semantics carefully. Note that bird:fly and pilot:fly appear to be the same lexical relation. But actually fly has more than one meaning. Bird is related to one sense and pilot to another. This becomes apparent when we look at the syntax of the sentences "The bird flew away," and "The pilot flew the airplane." The first sense of fly '(of a bird, insect, or bat) to move through the air using its wings' is intransitive and the second 'to operate (an airplane)' is transitive.
When you import data into Language Explorer, any data that does not map into one of the Language Explorer fields will be placed in one of the Import Residue fields. If the data relates to a particular sense, it will be put in the sense level Import Residue field for that sense. If it relates to the entire entry, it will be put into the entry level Import Residue field. You can use Bulk Copy or Click Copy to move data from the Import Residue field to any field you choose.
The Variants section is used to enter variants of the current lexeme. This assumes that the current lexeme is the basic form and that the forms entered here are variants of it. If the current lexeme is a variant, you should not use this section. Instead you should use the Variant Of field on the entry level to link the current (variant) lexeme to the basic form.
The Variants section is also used to enter irregularly inflected forms. Language Explorer handles variants and irregularly inflected forms in the same way. So whenever the program refers to "variants", you should understand it to be talking about irregularly inflected forms as well.
To add a variant, click somewhere on the Variants line, and then click the Insert Variant link. The Find Variant dialog box comes up, which enables you to type the form of the variant. If the variant is already in the database, Language Explorer creates a link between the entry for the basic form and the entry for the variant. If the variant is not yet in the database, Language Explorer creates an entry for it and links the two entries.
For each variant Language Explorer creates a bundle of four fields--Variant Form, Variant Type, Show Minor Entry, and Comment. You should enter the variant in the Variant Form field, specify what kind of variant it is in the Variant Type field, and then indicate if you want Language Explorer to create a minor entry for the variant by clicking the check box in the Show Minor Entry field. You can also add a note to yourself about the variant in the Comment field. You can add additional variants by repeating this same procedure.
Language Explorer creates a separate entry for each variant. This enables you to add extra information about the variant. The information from this section is copied into the entry for the variant. You will find each of these fields in the variant entry on the entry level. You can edit the fields in either entry and the information will be copied to the other entry. To show you how all this works I have put two entries side by side in the example below. On the left is the entry for the basic form. On the right is the entry for the variant. (The entries are two forms of the name for the city of Jerusalem in Koine Greek.[13]) The lines connect the corresponding fields in the two entries. The green lines point to the basic form. The red lines point to the variant form. The yellow lines connect the three fields that are copied from one entry to the other.
The Variant Form field displays the form of a variant. When you use the Variants section to add a variant, Language Explorer creates a separate entry for the variant and places the form of the variant in the Lexeme Form field of the other entry. It also places the form of the variant here in the Variant Form field of the entry for the basic form. In example (104) the red line connects the two fields. The two fields are copies of each other. A change in one field will also be made in the other field, because Language Explorer treats them both as a single object in the database.
Language Explorer also puts the headword from this entry into the Variant Of field of the other entry. The Variant Of field is located on the entry level of the variant entry. In example (104) the green line connects the two fields. So you can think of the Variant Form field and the Variant Of field as complementary fields. If you right click on either of the two fields, you can jump to the other entry. This enables you to quickly navigate between the basic form and the variant.
The Variant Type field is used to specify what type of variant is in the Variant Form field. The Variant Type field here in the Variants section of the basic form entry corresponds to the Variant Type field on the entry level in the entry for the variant. In example (104) the first yellow line connects the two fields in the two entries. You can specify the variant type of the variant in either place. The Variant Type field is a list field. The list is maintained in the Lists-Variant Types area.
The Show Minor Entry field is used to specify whether or not you want Language Explorer to create a minor entry for the variant. If this field is checked, Language Explorer will automatically create a minor entry for the variant. This field corresponds to the Show Minor Entry field in the entry for the variant. In example (104) the second yellow line connects the two fields in the two entries. You can change this field in either entry.
The Comment field is used to make a note to yourself about the variant in the Variant Form field. This field corresponds to the Comment field in the entry for the variant. In example (104) the third yellow line connects the two fields in the two entries. You can change this field in either entry.
The Allomorphs section is used to enter and constrain allomorphs of the lexeme. The primary or default allomorph should be entered in the Lexeme Form field and constrained (if necessary) there. To add an allomorph click on the Allomorphs line and then click the Insert Allomorph link. Language Explorer will insert a bundle of five fields--Stem Allomorph (or Affix Allomorph), Is Abstract Form, Morph Type, Environments, and Stem Name. The last four fields also occur on the entry level following the Lexeme Form field. You can add additional allomorphs by clicking again on Insert Allomorph. For more on handling allomorphs see section 3.2.1.
The name of this field varies depending on the choice you made in the Morph Type field. If you chose one of the affix types, this field will be called Affix Allomorph. But if you chose one of the root, stem, or phrase types, this field will be called Stem Allomorph. The Stem/Affix Allomorph field is used to enter the form of an allomorph.
The Is Abstract Form field is used to indicate whether an allomorph is an abstract form or an orthographic form. Some linguists want to enter an abstract form in the Lexeme Form field, the Stem Allomorph field, or the Affix Allomorph field. To prevent the parser from trying to use an abstract form, you should put a check in the Is Abstract Form field. For more on abstract forms see section 6.2.1.2.
The Morph Type field is used to indicate the morpheme type of the allomorph. For more on morpheme types see section 5.5.12.
The Environments field is used to specify one or more phonological environments that this allomorph can occur in. For more on environments see 6.2.1.4.
The Stem Name field is used to label an allomorph that is conditioned by a grammatical context rather than a phonological context. For more on stem names see 6.2.1.5.
The Grammatical Info Details section is used to store each of the grammatical categories that you have used in the entry. A lexeme can have senses that belong to different grammatical categories. For instance the word love can be both a verb (He loves me.) and a noun (His love for me means so much.). The word along can be used as a preposition (We walked along the river.) and as an adverb (Do you want to go along?). Each grammatical category used in the entry is stored in the Grammatical Info Details section and can be used for more than one sense.
The grammatical information for a sense includes more than just the category. So each category includes a bundle of associated fields. The grammatical category itself goes in the Category Info field and each bundle includes an Inflection Class field, Inflection Features field, and an Exception "Features" field. When you assign a grammatical category to a sense, you are actually assigning the entire bundle to the sense. This is why the grammatical field on the sense level is called Grammatical Info and not just "Grammatical Category".
Once you have described the grammatical information for a sense by filling out each of the fields in the bundle, you can reuse the bundle for other senses. You can also create a new bundle. You create a new bundle by adding a new sense. Then in the Grammatical Info field on the sense level you must assign the sense to a grammatical category instead of the previous bundle. Language Explorer then creates a new bundle in the Grammatical Info Details section. You can only fill out the other fields in the bundle in the Grammatical Info Details section. If you then create a third sense, you can assign it to one of the bundles you already have, or you can create a third bundle by assigning the sense to a grammatical category.
The Category Info field is used to specify the grammatical category of a sense. Usually you would specify the grammatical category of a lexeme when you create the entry. For instance the New Entry dialog box has a place to indicate the grammatical category. When you do this, Language Explorer creates an entry with a single sense and assigns the grammatical category to the first sense. You can also specify the grammatical category of a sense in the Grammatical Info field on the sense level. If you use either of these methods, the grammatical category will be displayed in the Category Info field. However if you have not yet indicated the grammatical category, you can do so in the Category Info field. The Category Info field is a list field. The list is maintained in the Grammar-Category Edit area.
The Inflection Class field is used to assign a lexeme (or more properly a sense of a lexeme) to an inflection class. An inflection class is a subset of a grammatical category that uses a unique set of inflectional affixes. For instance the English nouns that form their plural by adding -s (e.g. boy/boys, dog/dogs) form an inflection class. The nouns that form their plural by changing their vowel (e.g. man/men, goose/geese) form a second inflection class. You must create and maintain a list of inflection classes for each grammatical category in your language that has inflection classes. The lists are maintained in the Grammar-Category Edit area under the relevant grammatical category. If your language does not have inflection classes, you can ignore this field.
The Inflection Class field is used by the parser to correctly analyze inflected words. Most dictionaries indicate the inflection class of a word in the entry. Most native speakers of a language know the inflection class of a word. However children may not know it. Even adults may not know the correct inflection class of a rare or archaic word. For instance the Merriam-Webster Dictionary entry for goose handles it this way:
| (105) |
|
To produce this in Language Explorer you would need to set up a custom field for the plural form and use Configure Dictionary to insert "pl" before the contents of the field. The other alternative is to use Configure Dictionary to print the contents of the Inflection Class field. Since the Inflection Class field contains a class label and not the actual inflected form, this is not an especially good option. For instance the inflection class that goose belongs to might be labeled "vowel replacement plural." In Language Explorer this would come out like this:
| (106) |
|
This kind of label is not especially helpful for users who aren't linguists, which is why most dictionaries opt to use inflected forms to indicate inflection classes. For more on inflection classes see Andy Black's paper "Introduction to Parsing" in the Help-Resourses menu.
The Inflection Features field is used to assign an inflection feature to a lexeme (or more properly to a sense of a lexeme). An inflection feature is associated with a subset of a grammatical category that uses a unique set of inflectional affixes. Inflection features are also involved in syntactic agreement. The features sometimes correspond to broad semantic classes. In contrast, inflection classes are not involved in syntactic agreement nor do they correspond to semantic classes. Not all languages have inflection features. English has no inflection features, so it is necessary to use another language to illustrate how they work. Consider the following Greek words:
| (107) |
|
All Greek nouns have an inflection feature--gender, of which there are three values--feminine, masculine, and neuter. They also have case suffixes that indicate their syntactic role in the clause. The chart above gives an example of a noun from each of the three genders. Each noun is given with three (of the five) case suffixes--nominative, genitive, and neuter. The important thing to notice is that the form of the definite article is affected by the gender (and case) of the noun. In other words there is agreement between the form of the article and the gender of the noun. Notice also that there is no difference in the case suffixes of feminine and masculine nouns. However the nominative of neuter nouns has no suffix. So there is a difference in the case suffixes of neuter nouns. This is typical of inflection features. The affixes on the word can vary depending on the inflection feature, and other words take different affixes depending on the inflection feature of the noun (or other word) that owns the inflection feature.
How do we handle this in a dictionary? In order to correctly inflect a Greek noun, it is necessary to know its gender. So we must somehow indicate the gender of each noun in the dictionary. This can be accomplished in three ways. First, sometimes the gender can be indicated by the form of the noun. Some Greek derivational affixes determine the gender. For instance adding the derivational suffix -mat (cognate with English -ment) results in a noun that is neuter. The Greek noun gramma (γράμμα) 'letter' (from which we get our word grammar) is formed from the root graph (γραφ) and the suffix -mat. (The stem is grammat-, but the final t is deleted in the nominative because of a phonological rule.) At least to a speaker of Greek, the following entry indicates that gramma is a neuter noun. The fact that it is neuter is obvious from the citation form gramma, which is nominative, together with the genitive form grammatos, which follows it.
| (108) |
|
Unfortunately merely giving the form of the word does not always indicate the gender. The second way to indicate it is to add a label for the inflection feature after the grammatical category. Greek dictionaries sometimes do this by combining the grammatical category with the gender, as in 'nf' (noun-feminine), 'nm' (noun-masculine), or 'nn' (noun-neuter). The following masculine noun grammateus is an example.
| (109) |
|
However labels are often meaningless to users who are not linguists. So a third way to indicate the inflection feature is to add another word that agrees with the noun. In Greek dictionaries this is sometimes done by adding the correct form of the article. In the following entry for graphē the noun is feminine and this fact is indicated by the word hē (ἡ), which is the nominative feminine form of the definite article 'the'.
| (110) |
|
You can achieve any of these options in Language Explorer by setting up custom fields and using the Configure Dictionary tool, which is found under the Tools menu.
Bantu languages also have inflection features associated with the nouns. In Bantu linguistics these are usually called "noun classes." However they are inflection features, not inflection classes, because they are involved in agreement rules with other words in the clause. Bantu language dictionaries usually handle them in one of two ways. The first way is to give both the singular and plural forms of the noun. This is similar to the first option given above for Greek. The following Lugungu word illustrates this option:
| (111) |
|
To do this you would need to set up a custom field for the plural form. The second option is to include the inflection feature after the grammatical category. This is similar to the second option given above for Greek. In Bantu linguistics the "noun class" is indicated by two numbers. The first indicates what affix is used for the singular and the second indicates what affix is used for the plural. In Language Explorer the "1/2" would be the label for the inflection feature.
| (112) |
|
To do this you would need to use the Configure Dictionary tool to display the inflection feature.
You must create and maintain a list of inflection features for each grammatical category that has inflection features. The lists are maintained in the Grammar-Inflection Features area. Each inflection feature must then be listed in the Grammar-Category Edit area in the Features section of the relevant grammatical category. For more on inflection features see Andy Black's paper "Introduction to Parsing" in the Help-Resources menu.
The Exception "Features" field is used to assign an exception feature to stems and affixes. The Exception "Features" field is used by the parser to eliminate bad analyses. Some languages have affixes that can occur on some stems, but not others. If you have such an affix, you would create an exception feature and assign it to the affix. Then you would assign the same exception feature to each stem that takes the affix. The parser will then only allow the affix to cooccur with those stems that have the exception feature. I do not know of any dictionaries that include exception features. However you can use the Configure Dictionary tool to include them if you want. For more on exception features see Andy Black's paper "Introduction to Parsing" in the Help-Resources menu.
The Grammatical Info Details section is different when the entry is an inflectional affix rather than a stem. The following example is the Greek noun suffix -ς 'nominative'.
The -ς suffix is a noun inflectional suffix and occurs in the Case slot in the noun affix template. It also has the inflection feature 'gender-masculine'. It has no exception features.
The Category Info field is a virtual field that is automatically filled in on the basis of information that you have given about the affix.
For instance you may have given the information when you created the entry. However you can modify the information by clicking
on the field, clicking the  menu button and then selecting the correct values in the Edit Category Info dialog box. There are four pieces of information that are displayed in this field--the fact that the entry is an affix, the
affix type (inflectional or derivational), what grammatical category the affix attaches to, and what slot it fills in the
category template.
menu button and then selecting the correct values in the Edit Category Info dialog box. There are four pieces of information that are displayed in this field--the fact that the entry is an affix, the
affix type (inflectional or derivational), what grammatical category the affix attaches to, and what slot it fills in the
category template.
You can create a template for a grammatical category in the Grammar-Category Edit area. To create a template choose one of the grammatical categories, click on the Affix Templates line, and then click the Insert Affix Template link. You then set up slots in the template and assign each suffix to the correct slot. Once you have done this, the slot that an affix belongs to will be displayed in the Category Info field and the Slots field.
The Slots field displays the slot in the affix template that you have assigned the affix to. You would not normally display this field in a published dictionary. For more on affix templates and their slots see section 6.2.6.1 and Andy Black's paper "Introduction to Parsing" in the Help-Resources menu.
The Inflection Features field is used to assign the affix to an inflection feature. You would not normally display this field in a published dictionary. For more on inflection features see section 6.2.5.3 and Andy Black's paper "Introduction to Parsing" in the Help-Resources menu.
The Exception "Features" field is used to assign the affix to an exception feature. You would not normally display this field in a published dictionary. For more on exception features see Andy Black's paper "Introduction to Parsing" in the Help-Resources menu.
The Grammatical Info Details section is different when the entry is an derivational affix rather than a stem. The following example is the English suffix -ion.
The -ion suffix only occurs on roots and stems that have been borrowed from Latin. That is the reason for the "Latinate" exception feature. The "From" root (or stem) must be Latinate, and the resulting "To" stem is also Latinate. So the exception feature must be in both fields.
Derivational affixes often change the root from one grammatical category to a different grammatical category. This is the reason why there is a set of fields that start with "From" and a second set that start with "To." The "From" fields describe the grammatical category of the root, and the "To" fields describe the grammatical category of the resulting stem.
It is highly unlikely that any of these fields would be displayed in a published dictionary. The only exception is the grammatical category, as in example (114). For more on derivational affixes see Andy Black's paper "Introduction to Parsing" in the Help-Resources menu.
Endnotes
| [1] |
I'm not aware of any affordable software designed for the production of mirror image bilingual dictionaries. Such software could have nice features. But the production of full L1-L2 and L2-L1 dictionaries effectively doubles the amount of work required and therefore the amount of financial and personnel resources required. For most minority languages with severely limited resources such a goal is out of the question. It is hard enough to produce a single monolingual or vernacular-national language dictionary. |
| [2] |
I had the same experience when I started using the text corpus method in 1979. I was surprised at how frequently definitions failed to describe how words were actually used. In contrast I am frequently delighted at the insights found in definitions based on corpus studies. |
| [3] |
There is much debate concerning the nature of the 'minimal semantic unit' corresponding to a phoneme or morpheme. Here we use 'lexeme' to refer to a lexical unit that cuts across the phonological, grammatical, and semantic strata. |
| [4] |
A clitic is a morpheme that is a separate word in the grammar, but does not function as a separate word in the phonology. Instead it attaches itself phonologically to one of the words on either side of it. If it attaches to the word before it, we call it an enclitic. If it attaches itself to the word after it, we call it a proclitic. |
| [5] |
The symbols that you use to indicate that a form is an affix or other type of morpheme are called 'tokens'. You can change the Leading Token and/or Trailing Token in the Lists--Morpheme Type area. For instance if your language uses a hyphen as a word forming character, you can change the token for affixes from a hyphen to an equal sign. |
| [6] |
An alternative strategy is to enter all inflectional and derivational affixes into the database. In order to prevent the parser from using the derivational affixes, you could temporarily add something like 'zzz' to the end of the Lexeme Form of each derivational affix. This could be added (and later removed) by the Bulk Edit Entries--Bulk Replace tool. |
| [7] |
I coined the term 'minor subentry' to describe the combination of a minor entry and subentry. |
| [8] |
There is a work-around for this problem. You can create a temporary project in FieldWorks and import the word list as a list of lexemes. Then you can use the Bulk Edit tools to strip off affixes. Once you have reduced the words to the correct citation form, you can export it, merge duplicate entries (this can be done with the DDP CC table mergerec.cc), and import it into your permanent dictionary project. |
| [9] |
There is a way to automatically classify words using Consistent Changes tables. It works by matching an English gloss in your dictionary to the sample words in the DDP materials. Tests have shown that it can successfully classify 60-70% of the senses in a dictionary. However this requires that you export your dictionary from Language Explorer, run the CC tables, then reimport your dictionary. The CC tables cannot distinguish homonyms and multiple senses of a word. So there will be mistakes in the output that have to be corrected. |
| [10] |
My favorite in this list is "000 - Material Not Relevant". I really wish someone would explain why this is in the list. <grin> |
| [11] |
The difficulty in analyzing the derivational morphology of English is the reason why root dictionaries are not popular for English. |
| [12] |
I found the scientific name for the plant on Wikipedia (http://en.wikipedia.org/wiki/Clarinet). |
| [13] |
The word 'Jerusalem' was borrowed from Hebrew into Greek. The basic form is the form that was adapted to the phonology of Greek and would be the form that was used by most speakers of Greek. The variant form is transliterated from Hebrew and probably was pronounced close to or the same as the original Hebrew word. It was used by Jews living in Jerusalem and Judea who considered the city to be sacred. Some of the writers of the New Testament use both forms and the rules governing which form to use are quite complex and interesting. |
References
Louw, Johannes P. and Eugene A. Nida. 1989. Greek-English lexicon of the New Testament: based on semantic domains, Vol. 1. New York: United Bible Societies.
McKechnie, Jean L. 1976. Webster's new twentieth century dictionary unabridged. New York: Collins World.
Morris, William. (ed.). 1978. American Heritage Dictionary. Boston: Houghton Mifflin.
Summers, Della. (ed.). 1993. Language Activator. London: Longman.
Summers, Della, and Adam Gadsby (eds.). 2002. Longman dictionary of American English. 2nd ed. White Plains, NY: Longman.
Woolf, Henry Bosley. 1974. The Merrian-Webster dictionary. New York: Wallaby.